文|博阳
编辑|徐青阳
近期,谷歌的 Nested Learning 引发了一场模型界的记忆地震。
很多人重新意识到,大模型不必永远是「训练完就封存」的只读权重,它也可以在推理过程中继续变化。在 Nested Learning 里,当模型读到新的上下文时,它不只是把文本塞进注意力的缓存里临时翻找,而是允许自己在推理过程中更改参数,让新信息变成它内部记忆的一部分。
但就在人们还在消化这个想法时,英伟达在2025年12月28日给出了一个更激进的答案,一篇名为《End-to-End Test-Time Training for Long Context》的论文。谷歌的记忆增强路线,还在努力解决记忆问题,把过去重要的东西保存得更完整。但英伟达的研究人员则认为,记忆其实就是学习,「记住」就是「继续训练」。

就像人不会记得小学时的课文字句,但像《丰碑》这种文章当时给我们的感受,会深深塑造我们之后的价值观。
英伟达和斯坦福的研究者们相信,AI也应该这样工作。
01
用学习,替代注意力式的记忆
如果沿着时间线往回翻,你会发现 TTT(test-time training)并不是凭空出现的发明。
早在2013年,Mikolov 等人就在语言模型里尝试过 dynamic evaluation。当时放的是让模型解除冻结,在测试文本上继续用下一词预测的交叉熵损失 CE(也就是我们最经常理解的大语言模型的参数学习损失目标)做小步梯度更新,让参数对当前文体、主题、局部统计规律发生适应。Krause 等人在 2018 年把它完善得更系统,更可行。
也就是说,在大语言模型的早期,大家已经发现了模型在推理时动参数,即不违背语言建模的基本逻辑,甚至能带来收益。
在分析Nested Learning时候,大家都在讨论记忆力的革新。但很少人会注意到它在上下文这个语境下,对注意力层的替代。但TTT-E2E 的出现,更明确的提出这个可能性。
过去十年,Transformer 的辉煌建立在很大程度建立在注意力机制上。它把读过的每一句话都做成索引(KV Cache),每次回答问题都要回过头去精准翻阅旧书 。这种机制精确,但非常耗费内存。因此也有了各种群组注意力、线性注意力的改良方针,试图压缩其内存占用,提升模型的上下文长度。
而TTT的方案,则是直接放弃通过「内化」(权重更新)知识,来解决上下文处理的问题。无论上下文多长,它的推理状态大小和计算量都是永远不变的。
因此在TTT家族中,不论上下文如何增长,其Latency(生成延迟)都不会有任何变化。
这是TTT带来的,足以在推理阶段替代的注意力的核心能力:无延迟的记住近乎无限的上下文。
但dynamic evaluation 那条线一直没真正变成主流部署范式。这是因为它当时在工程上还很稚嫩,很难被有效地使用。这里的主要Gap存在于训练阶段和推理阶段无法对齐。
训练阶段优化的是「冻结参数时开箱即用的表现」,却没有把「推理时将进行若干步更新」这件事当作模型行为的一部分写进目标函数。这就导致工程现实中充满了不稳定性,模型在没有约束的情况下持续更新,灾难性遗忘(学新的忘了旧的)、参数漂移(模型参数分布变得很怪)、对异常片段的过拟合(会重复说奇怪话)就会变成默认风险。
早期方法能缓解的手段主要是「小学习率、少步数、勤重置」,它们能让系统勉强可用,但也几乎把 TTT 锁死在“短暂适应”的尺度上,很难发展成真正的长期记忆。
而Nested Learning / Titans所做的,正是把这套逻辑从架构层面上变得可行。通过分开不同更新频率的层级,让各层独自更新这种方式,稳定了参数更新。这也让TTT从短微调发展成长期内部记忆的方式。因此,我们可以说它带来了稳定的长程记忆更新方式。
不过这是有代价的。英伟达在论文里把Nested Learning、Titans 这一支,归到 TTT‑KVB 上。因为它们的更新目标其实和传统TTT有些不同。它们更像是在教模型「怎么存」,而不是直接教它「怎么预测」。
我们都知道,大语言模型的最终目标是「预测下一个token」,这是原初的学习目的。而Nested Learning的更新目标通常是让模型从某种压缩表示(如 key)重构出对应的 value,或者让隐状态在层内自洽地演化,这些都是为了构建可快速索引的内部记忆结构。这样做确实可以间接帮助语言模型完成任务,因为更好的内部关联记忆可能带来更好的预测。但它与最终目标之间始终隔着一层距离。
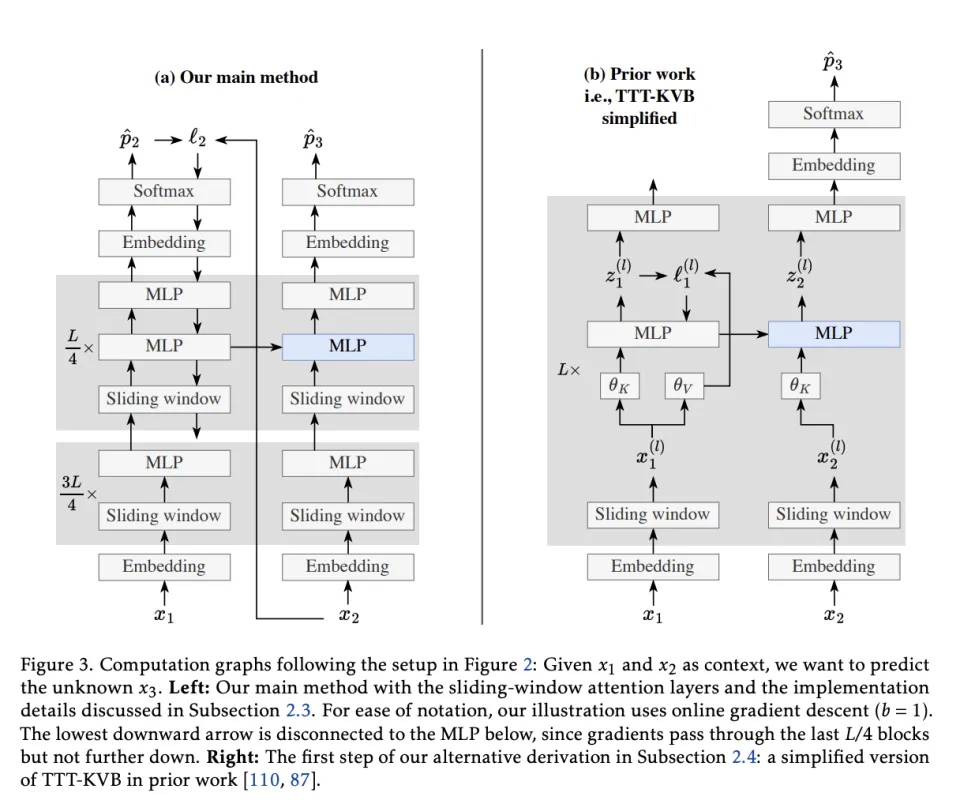
而英伟达提出的TTT‑E2E 则更像最原初的dynamic evaluation,它的测试时更新目标就是整个网络末端的下一词预测交叉熵 CE。为了做到只有一个目标,这个方法端到端的,不分层,从头到尾只更新这一个CE。当损失函数就是最终任务本身时,模型在上下文里学到的任何东西,都更直接地优化了后续预测。与模型的最终目标完全对齐。
为了把这个差别说明白,他们在论文里设计了一个「玩具模型」,在Transformer中移除了所有的自注意力层,只留下多层感知机(MLP)。这基本上把模型降级成了一个只能记住前一个词的「二元语法模型」(bigram),在这种设定下,任何长程记忆能力都不可能来自注意力或缓存,只能来自「你在测试时更新权重,把上下文压进参数」这件事本身。
然后在测试时,他们让模型在读到 x1 ,x2 ,x3 ,… 时不断做练习:用 xt−1 预测 xt ,计算 CE,并对这个损失做一次小步梯度下降。
这像是一个只能看清脚下一米的探险者,只能凭刚迈出的那一步来猜下一步。而你需要穿越一个10公里的洞穴(历遍所有上下文及更改)。
- 每走一步,你会先预测”根据我的方向感,下一步我应该看到岩石还是水坑?”
- 然后走一步,看预测对不对。
- 如果错了,你就调整身体的姿态和步伐(梯度更新)。
- 在「预测—纠正—调整」的循环里改变了你的「肌肉记忆」(权重)
走到第1000步时,你虽然看不到第1步那里的巨石,但那块巨石的信息已经编码在你此刻的步态、重心和方向感里了。它通过999次的「预测-纠正-调整」传递下来,融入了你的身体。
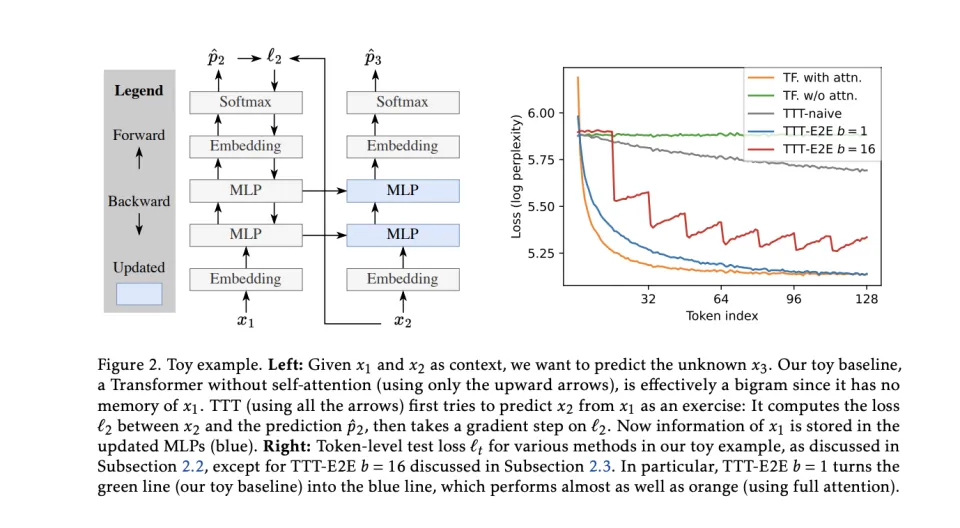
结果,这个没有任何注意力缓存的模型,靠着「训练对一下词的预测」这个目标Loss 曲线(蓝色)随着阅读长度的增加迅速下降 。它几乎紧贴着全注意力 Transformer 的曲线(橙色线)。
这意味着,它单纯靠修改自己的神经网络参数(MLP权重),就完美编码了上下文信息,达到了和把所有字都存下来(Full Attention)几乎一样的效果。
相比之下,TTT‑KVB 的设计初衷是作为一个自注意力层的直接替代品。它的核心思想仍然是「键值绑定」(Key-Value Binding)。也就是说,它虽然不用传统的注意力机制去 存储 KV Cache,但它试图用神经网络去学习 Key 和 Value 之间的映射关系。
这就像希望把洞穴每块石头都画在地图上,去随时调用。甚至巨石的纹理这种和走出洞穴无关的信息也会画进去。它的训练效率相对就比较慢。
论文在过渡实验结果中证明了这一点。研究人员把 TTT‑KVB 的层内键值绑定这个目标替换为预测端到端的 next-token 目标后,语言建模的评估 loss 明显下降。
从实验数据看,这个改变确实带来了实质性的提升。在760M参数的模型上,TTT-KVB在8K上下文的loss为2.818,而将其简化版本改用next-token prediction损失后(TTT-E2E all layers MH),loss降至2.806。

这提升的0.012,在语言模型评估中其实是显著的差距。这说明了,经过端到端的改造,模型对于预测下一个token这件事确实更确信,更擅长了。而且长上下文能力真的可以纯靠测试时学习获得,而不必依赖注意力缓存。
在这个逻辑下,记忆不再被设计成一套存储结构,而被重新定义为一次持续发生的学习过程。记忆的价值不在于把过去保存得多完整,而在于它能否改变你下一步的判断。
但是,过去的dynamic evaluation的问题就在于没有稳定的工程模式,既然要用一样的思路,TTT‑E2E怎么克服这些问题呢?
这正是英伟达接下来要做的第二件事:用元学习与一整套工程护栏把这种端到端的测试时学习做成稳定、可扩展的上下文记忆系统。
02
元学习的回响,和工程的稳定
元学习,这个概念和实践实际上也出现的很早。其中有一支显性元学习的想法一直到去年发布的Deepmind DiscoRL 都被继承着。
这就是2017 年Finn 的 MAML体系。它是由内外两个循环嵌套而成,内循环负责适应学习(梯度下降),外循环负责把适应学习变得更有效(学习梯度的梯度)。这样,外面那层循环更像是对内循环步骤的反思,通过它,就可以学会如何高效的学习。
TTT‑E2E所做的,正是利用这一套元学习的体系,帮助它去稳定端到端的数据。
英伟达的研究人员认为,过去dynamic evaluation的问题,主要在「训练-测试不匹配」上。如果只用传统方式训练一个冻结的语言模型,然后在测试时突然要求它边读边更新参数,那整体肯定稳定不了,灾难性的漂移、遗忘都是常事。因此,训练阶段就要把测试阶段的学习流程包含进去,让模型在出厂时就习惯在推理时继续学。
这就是元学习入场的时候。它要在训练时帮助模型学会怎样更新自己,才能更会回答接下来的问题。具体的操作,就是利用元学习,让模型自己找到最适合推理时更新的初始参数W0。
把它写成更直观的过程,就是两段循环套在一起。
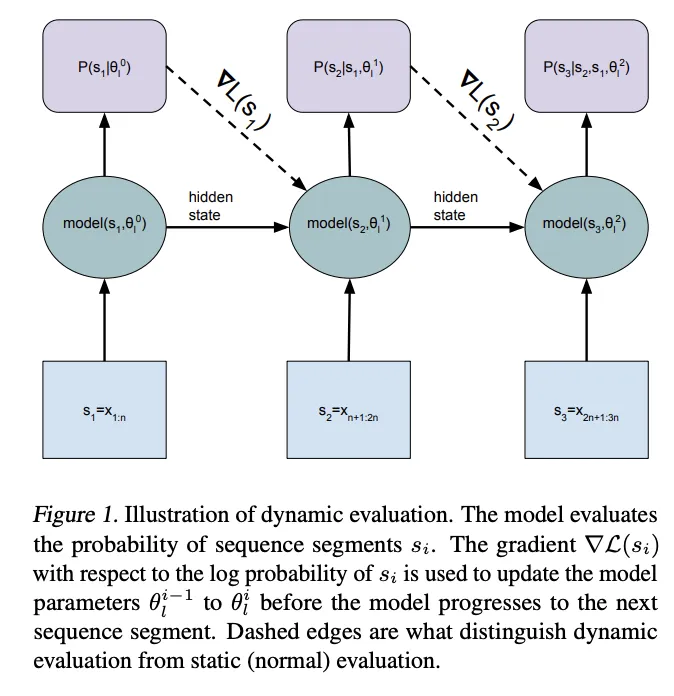
内循环:就是模型读到一段上下文时,给出下一个词的猜测。然后立刻对照实际上出现的下一个词,去更新自己的参数。这和传统的下一个token 预测模型的训练一致。
外循环:是在训练阶段给内循环反复模拟「上岗状态」。它给内循环的模型很多段文本,让它按同样的复盘方式做几次小校正,然后检查校正之后,内循环后面的预测是不是确实更准、更稳。只有当内循环的参数更新真的带来收益时,外循环才奖励它,如果这种更新方式会造成漂移或遗忘,外循环就惩罚它。久而久之,模型学到了一种更合适的出厂状态。带着这些初始参数去上岗,内循环的小校正(梯度更新)就不容易把自己改坏。
外循环的教师,在这里学到的是在测试时更新中,哪些方向的梯度更新是稳定的(防止梯度爆炸),哪些更新能在不破坏通用能力的前提下快速吸收上下文规律(防止灾难性遗忘),哪些初始化让同样的学习率、同样的步数能产生更可靠的收益(提升训练效率)。再把这些都融合到模型初始的参数里。
一个元学习,直接让模型自己解决核心的工程困境,使得端到端的模式变为了可能。
但这仅仅是可能,并不是达到了稳定。为了进一步确保工程上的可能性,TTT‑E2E还是在工程中做了多重折中的安全阀。
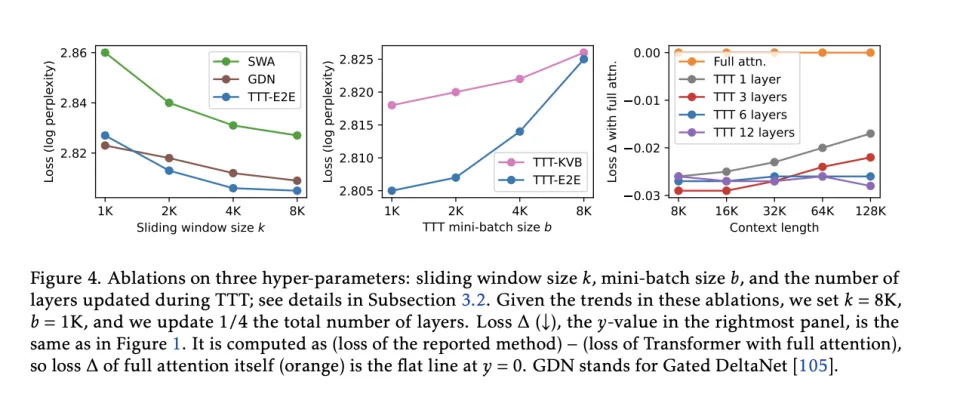
第一个安全阀是 mini‑batch 化和滑动窗口注意力。理论上讲,在测试时每读一个 token 就更新一次参数,是最细粒度、最完美的在线学习,但它可成本太高了。但每次给他的的token batch太大,模型又根本没有短期记忆,那么它在更新之前对一个batch里吼main的 token 就根本记不住,梯度也会越来越错。
所以,TTT‑E2E一方面把batch的大小做到相对较小。而且还保留滑动窗口注意力作为短期记忆的方法。窗口注意力像手电筒,保证你在一个更新块内至少还看得见最近的上下文,从而让 block 内的预测不至于崩坏。
论文明确提出了一个窗口大小和batch大小的规范,即窗口大小 k 最好不小于测试时更新的块大小 b,否则你会在块内变回「局部失忆」的模型。
第二个安全阀,目标是防止。他们没有非常激进的把所有层都改成TTT层。而是冻结了 embedding、归一化和注意力层,只更新 MLP。并且每次不更新整个神经网络,只更新最后 1/4 的 blocks。
这样底层的通用语言能力、注意力的读写通道保持不动,TTT只在上层做一种可控的学习模块。为了进一步防止在线更新把预训练知识冲掉,他们还在可更新的 blocks 里加了一套静态的第二 MLP。有一套MLP 负责写入当下上下文,另一套负责保住出厂能力。
这是在结构上给灾难性遗忘划了一片隔离区。参数可以漂移抹去过去的记忆,但只能在一块被圈起来的可写区里漂移。
当这些部件拼好时,TTT-E2E终于实现了最早版本TTT未竟的目标,为它带来了完整的工程化躯体。
那么它的结果如何呢?
03
用Loss证明自己
我们看模型训练效果,最主要的是看模型的loss变化。loss 指的是语言模型在下一词预测任务上的平均损失,一般就是上面说的交叉熵CE的大小。它越小,说明模型预测越准。
而在记忆中,则是看loss在上下文中的变化。如果 loss 在更长上下文里持续下降,说明模型确实把更早的信息用起来了,预测的更好了。反之,如果上下文变长但 loss 不降反升,说明信息虽然记住了,但没用,属于学而不思则惘了。
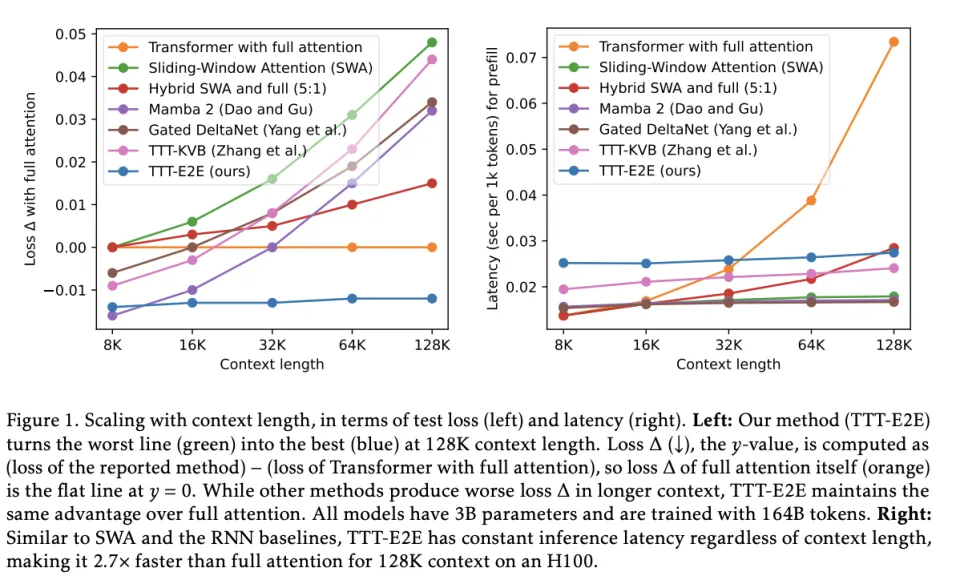
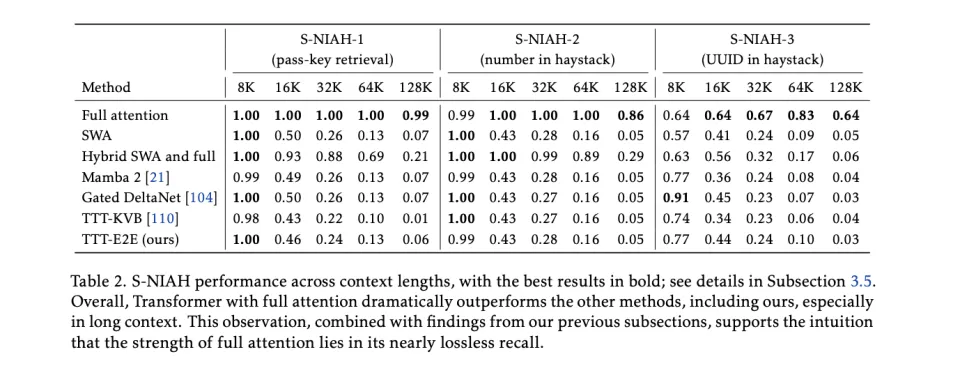
在这一项上,TTT‑E2E的优势非常明显。当上下文一路加到 64K、128K时,其他类型的架构,比如Mamba 2、Gated DeltaNet 这些线性时间模型就开始掉队了,甚至连 TTT‑KVB,在更长上下文里也没能把曲线拉回来。
只有 TTT‑E2E 的线几乎像钉住了一样,从 8K 到 128K 没有出现优势稀释的迹象。这说明别人是上下文越长越难学到,而TTT‑E2E 则是越跑越会用上下文。
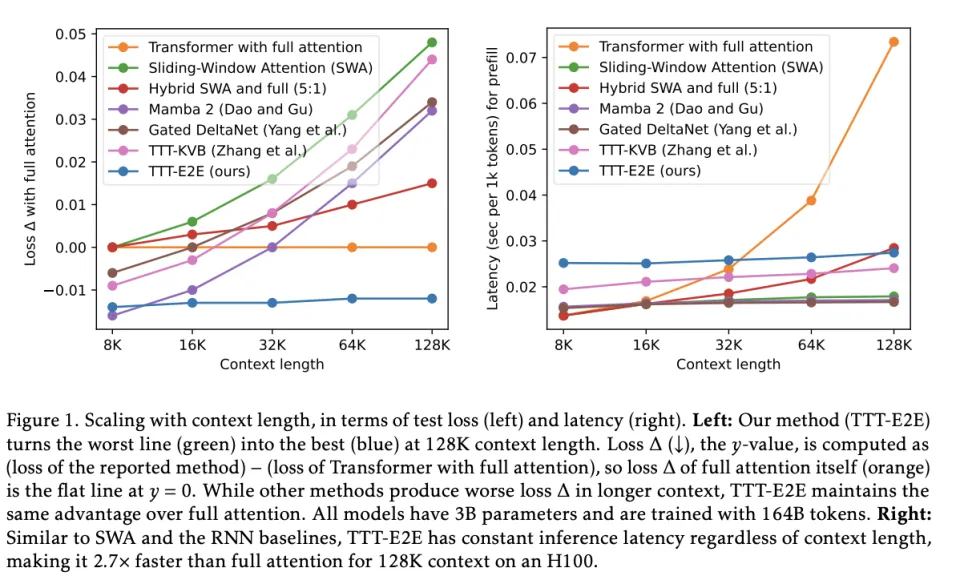
而且,它也延续了学习参数最大的优势,就是成本压缩。如果用全注意力,上下文越长,prefill 的延迟就会一路飙升,因为它每生成一步都要扫描更长的历史。相反,SWA、RNN/SSM、TTT‑KVB、TTT‑E2E 的延迟几乎是平的。它是靠学进去,而不是一直看着旧上下文去处理新的上下文的。在 H100 上,128K prefill 时,TTT‑E2E 大约比 full attention 快 2.7×。
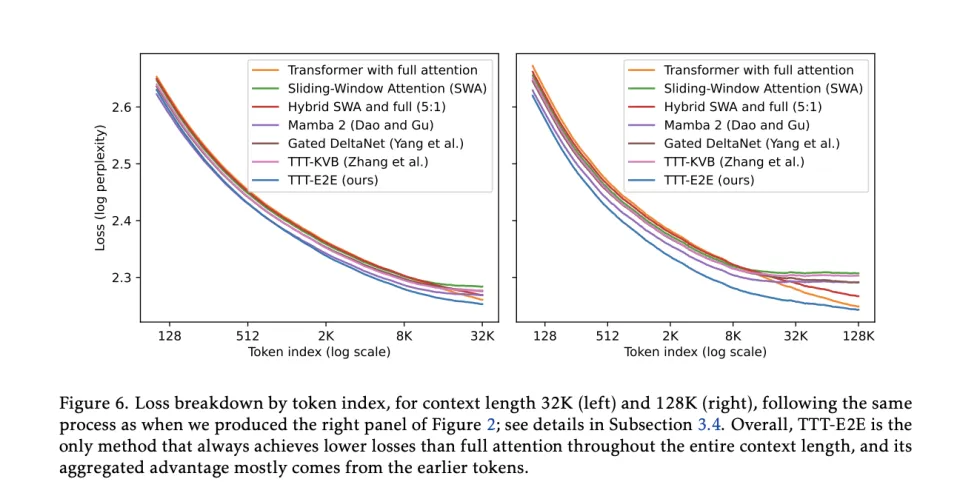
另一项,则是看Loss的收敛速度,Loss收敛的越快,说明模型越高效的在学习。在 32K 和 128K 两种长度下,TTT‑E2E 是唯一一种在整个上下文范围里都能压过 full attention 的方法,而且它的总体优势有很大一部分来自序列更早的位置。
这正是「学习而非存储」发挥特长的地方。模型不是等到最后才靠记忆取回某个细节,而是从一开始就让每一段上下文都在把模型推向更适合下一段预测的参数区域。它是在背书,更是在边读边形成更适合这本书的阅读习惯。
当然,这种方法并非面面俱到。TTT‑E2E 在海底寻针这种需要精确检索的测试上仍然被full attention碾压,包括 TTT‑E2E在内的线性路线一直在长上下文检索上表现并不好。
这并不矛盾,当记忆被定义为「学习带来的预测收益」时,它就更像压缩和概括,而不是逐字存档。对写作连贯性、长文理解、风格约束这种任务,这种压缩很划算。用学习压缩换取长上下文的可扩展性,让模型在 128K 这样的尺度上既跑得动,跑得省,又确实变得更会预测。
这就是TTT的核心意义之一。
另外一个可能制约这种架构落地的因素,是训练成本。即使有了各种优化,TTT-E2E的训练延迟仍然比标准Transformer高出50-100%。这在学术研究的规模上可以接受,但当扩展到工业级的数万亿token训练时,这个额外成本就有点略高了。
04
回归原初的学习,可能才更符合持续学习的期待
Nested Learning 这场革命的意义,是再一次把「推理时更新」从过去的沉寂中带入了当下的讨论的范畴,让持续学习找到了新发力点。
TTT-E2E 的意义,不只是又一个长上下文方案,而是重新定义了记忆这件事。记忆不是把过去搬进现在,而是让过去改变未来。
在注意力机制因二次方成本而逼近物理极限的今天,这种‘把信息学进参数’的路线,可能是唯一能让模型真正从百万 token 上下文里持续成长的工程答案。
在一个上下文窗口越来越长、信息越来越多、但人们越来越不愿意为传统注意力二次方成本买单的时代,这种把记忆当作学习、把学习当作压缩的路线,可能会在相当长一段时间里成为持续学习最现实的工程答案之一。
它不一定无所不能,但它比当下的任何记忆方案都更接近我们对智能的本质期待:「不是记住一切,而是能从一切中学会变聪明」。
– End –
转载请注明:好奇网 » 谷歌刚掀了模型记忆的桌子,英伟达又革了注意力的命|Hao好聊论文