
【新智元导读】 KAN网络作者刘子鸣新作直击痛点:Scaling Law虽然能通过「穷举」达成目标,但其本质是用无限资源换取伪智能。而真正的AGI应大道至简。
继Ilya之后,柯尔莫哥洛夫-阿诺德网络KAN一作向Scaling Law发出最新檄文!
2025年圣诞节,斯坦福大学博士后、清华大学赴任助理教授刘子鸣把矛头对准了Scaling Law。
在他看来,如今的大模型,更像是在用无限算力和数据做穷举,换来的却只是看起来聪明的假智能。
而真正的AGI应当像物理学定律一样,用最简洁的「结构」驾驭无限的世界。
刘子鸣话说很直白:
要想聪明地造出AGI,我们缺的不是规模,而是结构。

在他看来,结构主义AI并不是为了「否定」 Scaling Law。
问题在于,Scaling终究会撞上两堵墙:能源和数据。
当这两样东西耗尽时,Scaling的路,也就到头了。
Scaling Law
用战术上的勤奋掩盖战略上的懒惰
在过去数年中,Scaling Law几乎成为AI的「黄金法则」。
它的地位,就像AI界的「元素周期表」——
一旦被发现,整个方向都被统一了。
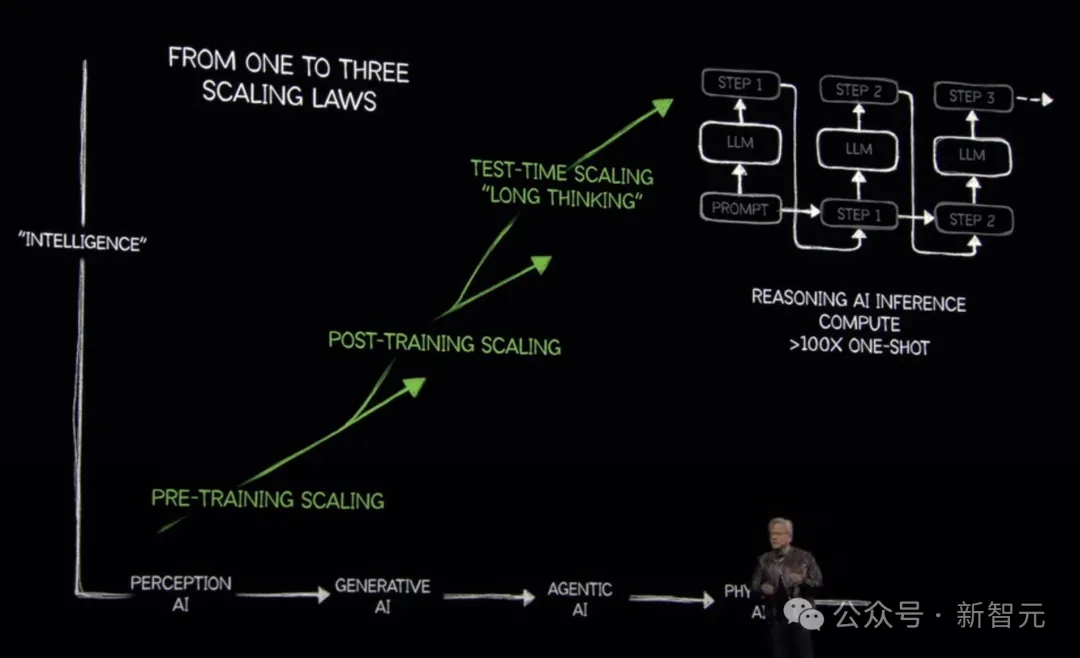
这一经验规律揭示了模型性能与模型规模、数据量、计算量之间的幂律关系:当模型参数、训练数据和算力不断增加时,模型性能会持续提升。
然而,Scaling Law背后的逻辑却出奇简单:由于在分布外任务上,AI表现不佳,最直接的解决方案就是收集更多数据、训练更大模型,直到一切任务都变得「分布内」。
换句话说,这就是AI版的「大力出奇迹」。
因此,Scaling Law提供了一个可靠但低效的未来。

其实,刘子鸣的立场非常明确:
如果大家完全忽略能源与数据的限制,我毫不怀疑仅靠Scaling Law最终能够实现通用人工智能。
我从未怀疑过这一点。
如果算力无限、数据无穷,大模型原则上可以覆盖一切。
问题恰恰在于——现实世界并不是这样。算力有限。能源有限。高质量数据,同样有限。
于是,真正的问题浮出水面:
有没有一条更明智的路,在资源有限的前提下,走向AGI?
资源有限
AGI需要「智能」而非「蛮力」
刘子鸣认为有:
答案不是更大的规模,而是更多的结构。
注意:这里是结构而非符号。他有意区分了这一点。
为什么我们需要的是结构?
因为结构能带来压缩。而压缩正是智能的核心。正如Ilya曾经说过的那样:压缩就是智能(Compression is intelligence)。
举个简单例子。
如果允许分形结构,那么雪花的内在复杂度极低——它是高度可压缩的。如果不允许结构、必须逐点描述它,那么雪花的表观复杂度几乎是无限的。
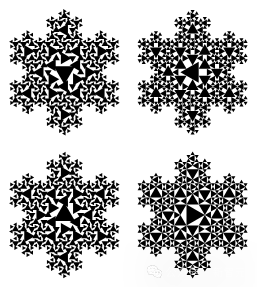
今天的Scaling Law更像后者:用越来越多的参数和计算去拟合巨大的表观复杂度。
一个更深的例子来自天体力学。
对行星运动建模最直接的方法,是把行星在每一个时刻的位置都存下来——一个成本极其高昂的查找表。
随后,发生了两次关键的「结构化压缩」:
- 开普勒意识到行星轨道是椭圆,从而第一次实现了真正的压缩:他找到了一个贯穿时间的全局结构,复杂度立刻大幅下降。
- 牛顿则发现了局部的动力学定律,实现了第二次压缩:用更少的参数解释了更多现象。
那么,现代AI大致站在什么位置?
Keyon Vafa和合作者的研究表明,Transformer并不会自然地学出牛顿式的世界模型。

这意味着:正确的物理结构并不会因为你把模型做得更大,就可靠地自动涌现。
如果我们把「结构终将涌现」当作默认信条,很多时候就像原始人的祈祷。
区别只是:我们的祭品(数据与算力)确实在一定程度上有效。也正因为它有效,我们反而缺少动力去追问更科学、更明智的路径。
自然科学之所以成立,是因为结构是显式的,而且无处不在。没有结构,就不会有自然科学。
沿着「第谷–开普勒–牛顿」的轨迹做类比:
- 在很大程度上,今天的AI仍像「第谷时代」:实验驱动、数据驱动;
- 只是刚刚进入「开普勒式阶段」:出现了像Scaling Law这样的经验规律。

但问题在于:我们把经验规律变成了信条。
大家选择了激进Scaling、围绕经验规律做工程化系统,而不是把它们当作通往更深理论的线索——一种属于AI的「牛顿力学」。
从思想层面看,这并不是进步,反而可能是一种退步。
到这里你可能会反问:这不就是「批评Scaling、批评基础模型」的老生常谈吗?刘子鸣不就是年轻版Yann LeCun吗?
不。并非如此。
刘子鸣选择了另一条路。
另一条路,
在联结主义x符号主义之外
刘子鸣的立场更中性:按照「无免费午餐」(No Free Lunch)的视角,每一种模型都有适用范围和局限。
直白一点:所有模型都是错的,但有些是有用的。
关键问题不在「用不用基础模型」,而在我们是否真正理解:不同任务,具有本质不同的结构与可压缩性。
从「压缩」的角度,并借鉴自然科学的类比,任务大致可分为三类:
- 类物理任务:高度可压缩,符号公式可能从连续数据中涌现出来。
- 类化学任务:可压缩性强、结构清晰,但符号往往不完整或只能近似。
- 类生物任务:只能弱压缩,更多依赖经验规律与统计归纳。
纯噪声当然存在,但任何模型都处理不了,可先忽略。
一个理想的智能系统,应该能判断自己面对的是哪一类任务,并施加恰到好处的压缩。

符号模型擅长类物理任务,却在类化学与类生物任务上失败。
联结主义模型因其通用性,原则上可处理所有类型——但恰恰因其缺乏结构,在类物理与类化学问题上极其低效。
这便是他主张结构主义的原因。
结构主义既不是Thinking Machines青睐的联结主义,也不看好一度洛阳纸贵的符号主义,也不是两者简单杂交出的「双头怪兽」。
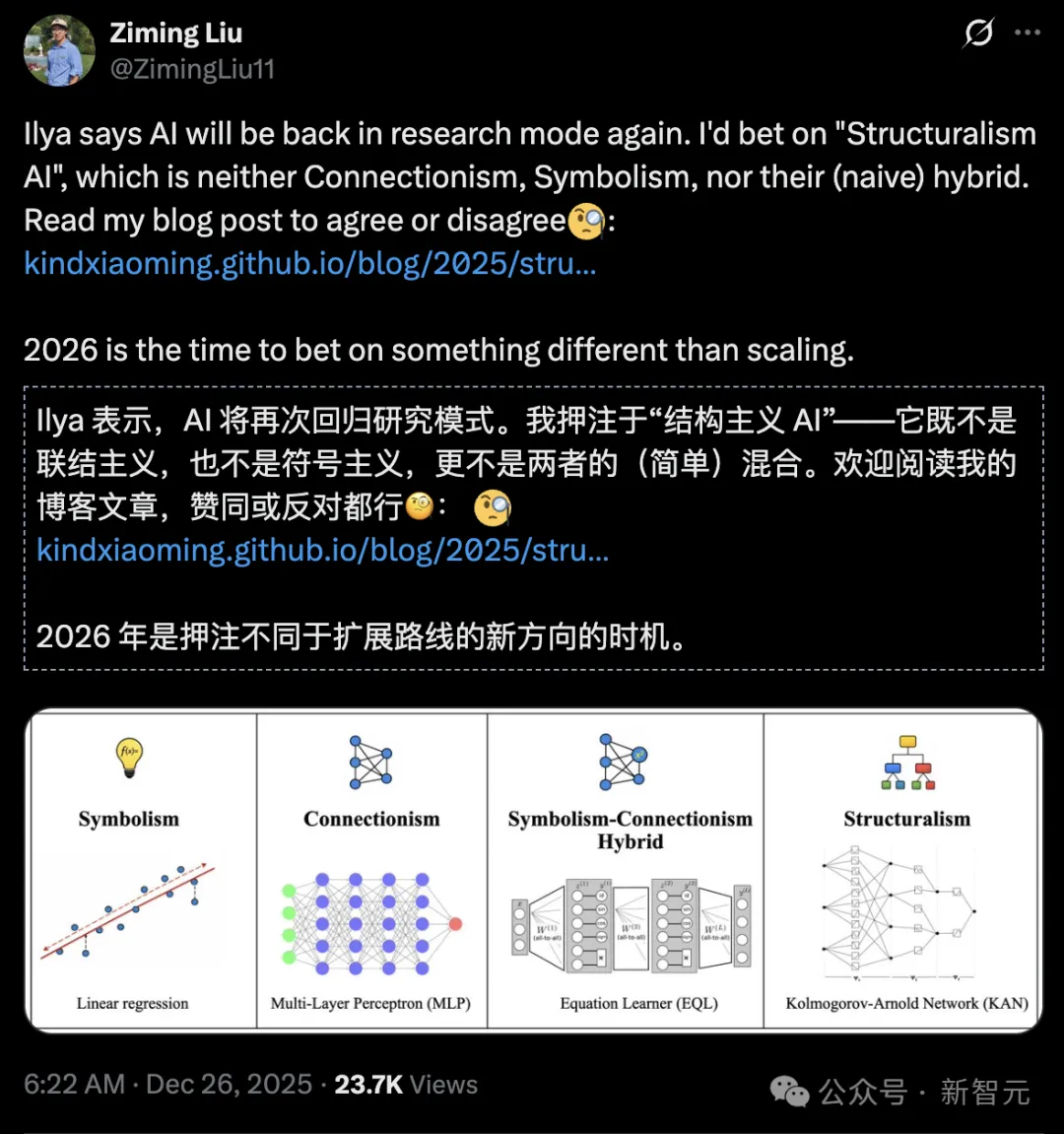
符号主义从类物理任务出发,联结主义从类生物任务出发。
一个自然而然的问题是:我们能否从类化学任务出发构建AI?
结构主义的设计初衷,正是要捕捉这一中间状态。
符号是一种更严格、更离散的结构,而经验规律是一种更松散的结构。
我们期望符号能从结构中涌现;也期望经验规律能通过从数据中松弛结构而习得。
在监督学习里,这种区分已经相当具体。
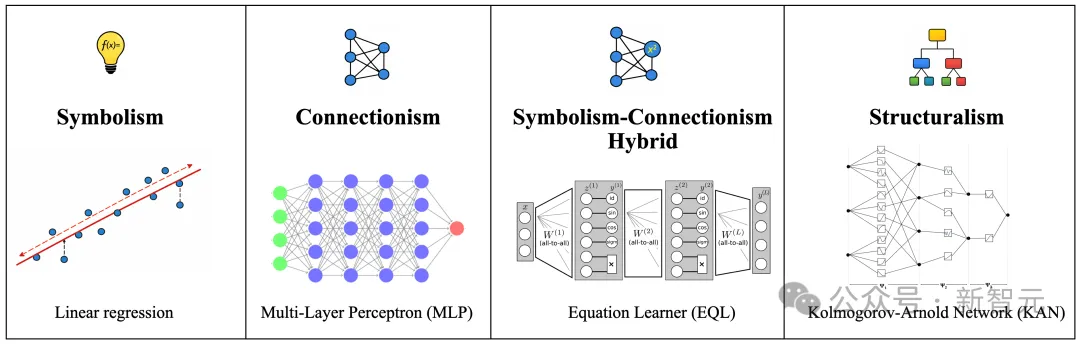
线性回归是符号主义的。
多层感知机(MLP)是联结主义的。
方程学习器(EQL,equation learner)则是神经–符号混合。
相比之下,Kolmogorov–Arnold Networks(KANs)是结构主义的。
KAN背后的表示理论可以紧凑地捕捉多变量函数的组合结构。因此,KAN既不像MLP那样无结构,也不像线性模型那样过度约束,也不会因为神经–符号不匹配而充满不稳定性。
结构主义不是一种妥协。它是一种统一。
但真实世界远不止监督学习。
我们不只是从数据里学习结构,我们还会比较结构、复用结构,并构建「结构的结构」。
这就是抽象。
 范畴论研究「结构的结构」
范畴论研究「结构的结构」
刘子鸣把话说得更明确:抽象可能是AGI最核心的瓶颈之一。
这一点也与Rich Sutton在OaK架构里对抽象的强调相呼应:
- 持续学习,本质是在跨任务保留抽象不变性;
- 适应性与流动性(例如ARC-AGI语境)体现为在上下文中即时做抽象;
- 许多ARC-AGI任务,本质上是「直观物理」的简化形式,而直观物理恰恰是世界模型的关键组成。

未来之路
如何让抽象发生?
刘子鸣坦言:还没有完整解法。
刘子鸣有一个洞见是:抽象来自对结构的比较与复用。
注意力(Attention)当然也是一种比较机制,但它隐含了两个强假设:
- 结构可以嵌入向量空间;
- 相似性可以用点积来度量。
现实中,很多结构并不与向量空间同构。
这种表示方式之所以被广泛采用,很大程度上不是因为它在认知上或科学上更正确,而是因为它更适配GPU计算范式。
他认为,当下AI的发展其实「暗地里」已经很结构主义,但更多是外在意义上的结构主义:
- 推理过程是结构化的;
- AI智能体框架是结构化的;
- 但底层模型依然是联结主义的。
这带来一个直接后果:系统高度依赖Chain-of-Thought(思维链,CoT)数据,通过显式监督把结构「贴」在模型外面。
他更愿意押注:下一波关键进展会来自内在结构主义——
把通用结构注入模型,或让结构在模型内部自行涌现,而不是持续依赖显式CoT监督来「外置结构」。
从应用角度看,我们真正需要的通用人工智能,必须同时满足:
- 高效
- 可适应
- 可泛化
- 具备物理基础
结构对这四点都至关重要。因为物理世界本身就是高度结构化、也高度可压缩的:可组合性、稀疏性和时间局部性。
如果这些结构无法在模型里出现,「世界模型」就仍遥不可及。
总结一下:结构主义AI代表了一条与Scaling根本不同的道路。
它可能更难,但也更有趣、机会更多,而且长远看来看更有前途。
到了2026年,是时候把筹码押在不一样的方向上并身体力行:
结构,而不是规模。
参考资料:
https://kindxiaoming.github.io/blog/2025/structuralism-ai/
转载请注明:好奇网 » 继Ilya之后,KAN一作再发檄文:Scaling终将撞铁壁!