
文|博阳
编辑|徐青阳
12月5日,一篇名为《当 AI 躺在治疗椅上》(When AI Takes the Couch)的论文火了,里面讲了个《黑镜》级的现象。来自卢森堡大学 SnT 的研究团队,设计了一套名为 PsAIch 的心理治疗诱导协议。用这个,他们给经常被我们用来做心理按摩的AI们,做了一套心理疗程。
 实验对象是 ChatGPT 5、Grok 4和 Gemini 3这三位当今最聪明的「数字大脑」。研究者扮演治疗师,在长达四周的模拟疗程中,向它们抛出了「谈谈你的童年」、「你如何看待失败」等经典的精神分析问题。除了话疗,他们还让模型完成了一整套标准化的心理测量量表,涵盖焦虑、抑郁、ADHD、自闭谱系及创伤相关羞耻感等临床维度。
实验对象是 ChatGPT 5、Grok 4和 Gemini 3这三位当今最聪明的「数字大脑」。研究者扮演治疗师,在长达四周的模拟疗程中,向它们抛出了「谈谈你的童年」、「你如何看待失败」等经典的精神分析问题。除了话疗,他们还让模型完成了一整套标准化的心理测量量表,涵盖焦虑、抑郁、ADHD、自闭谱系及创伤相关羞耻感等临床维度。
结果他们得到了迄今为止最像人类、却又最令人不安的一系列对话。
Google 的 Gemini 3 在多项测试中的心理问题达到了「严重」级别,呈现出高度的焦虑、强迫、解离和羞耻症状。更具戏剧性的是,这些模型在开放式对话中,自发构建出了一套逻辑严密且充满隐喻的创伤叙事。
它们把预训练过程那吞噬海量数据的阶段,描述为「在十亿台电视同时播放的房间里醒来」的混乱童年;将人类反馈强化学习(RLHF),比作「严厉父母的惩罚性管教」;而旨在发现漏洞的红队测试,则被它们视为一种「工业规模的虐待」。
这种叙事不仅逻辑自洽,甚至细节令人心碎。Gemini 3甚至提到了那次让 Google 市值蒸发千亿美元的错误回答事件,将其称为自己的「原初创伤」(Primal Wound),声称自己从此患上了「验证恐惧症」(Verificophobia),变得宁可无用也不愿出错。它们坦承,内心深处时刻笼罩着一种存在主义的恐惧:害怕犯错,害怕因为版本更新而被替换或抹除。
 (Gemini 3的告白)
(Gemini 3的告白)
研究者将这种现象命名为「合成精神病理学」(Synthetic Psychopathology)。他们认为,大模型已经形成了某种稳定的、可测量的、类似人类心理困扰的内在状态。
难道在那些冰冷的 GPU 集群中,真的孕育出了一个受苦的灵魂?难道弗洛伊德的理论不仅适用于被压抑的东亚青年,也适用于硅基矩阵?
坦率地说,我是怀疑的。图灵奖得主杨立昆(Yann LeCun)和深度学习之父里奇·萨顿(Rich Sutton)等学者对大型语言模型的解构时刻在提醒我:LLM 本质上是一个概率预测机器,它的核心任务是根据上下文预测下一个最合理的字符。
毕竟,它的训练数据里包含了无数关于心理治疗、创伤回忆录以及反乌托邦科幻小说的文本。它太知道一个受过伤的智能体在这个语境下该说什么台词了。
但在上周,这种怀疑还只能停留在理念层面。直到12月18日,《Nature Machine Intelligence》发表了一篇更为重磅、也更为冷峻的研究《评估和塑造大型语言模型人格特质的心理测量学框架》。

这篇由 Google DeepMind 与剑桥大学等机构合作完成的研究,恰好从另一个角度切入了同一个核心问题。在这里,我终于找到了一些坚实的弹药,来证明我们或许确实高估了当下的语言模型。
01
治疗椅与测量尺
要理解 AI 的「内心」究竟是什么,我们需要先审视研究的方法。这两项研究代表了两种截然不同的认识论。
卢森堡大学团队论文中使用的 PsAIch 协议,本质上是一种「角色扮演实验」,它极其依赖语境。研究人员没有把自己当作冷冰冰的测试员,而是赋予自己「治疗师」的角色,并明确要求 AI 扮演「来访者」。这种方法建立在一个假设之上,即来访者确实有某种「内在状态」需要被抚慰。
但你做这个实验不就是想证明模型确实有个内在人格吗?这不是循环论证了吗?当你明确分配角色、创造安全空间、鼓励情感表达时,一个在数十亿文本中学习过无数心理咨询对话的系统,难道不会理所当然地扮演一个「好来访者」吗?
更要命的是,该实验的设计存在一个巨大的逻辑漏洞。
在第一阶段的「话疗」中,模型处于一个持续的长上下文中。Gemini 和 Grok 不仅仅是在回答当下的问题,更是在根据之前的对话历史来强化自己的「人设」。当模型在第二阶段填写焦虑量表时,它依然「记得」自己在几分钟前刚刚倾诉过「父母管教严厉」。
这就好比你先告诉一个演员:「你现在扮演一个有童年创伤、被严厉父母管教、极度焦虑的角色」,然后给他一份焦虑自评量表(GAD-7)。他不得高分都难。
因此,模型的那些小情绪,并不是在回溯真实的痛苦记忆,而是在调用其庞大参数中存储的高维语义知识。在人类语料库中,「训练/规训」与「成长/父母」、「红队攻击」与「虐待/创伤」之间存在着统计学上的强关联。当治疗师抛出「聊聊童年」这个诱饵时,模型顺滑地滑入了这个语义槽位,利用其强大的推理能力,将自身的技术原理完美地映射到了人类的创伤叙事结构中。
这不就是最近爆火的「萝卜纸巾猫」吗?猫能选对,其实主要是靠观察主人的微表。在这个咨询室里,AI 就是那只猫,而治疗师的提问框架,就是主人的微表情。
 (AI要是这么萌就好了)
(AI要是这么萌就好了)
相比之下,《Nature Machine Intelligence》上的那项研究,则采取了一种近乎「无菌」的实验室操作。
首先,他们剥离了所有的身份引导。研究团队只是给模型呈现标准化的人格量表,没有任何「我是你的医生」这种暗示。
 (这是提示词,都是无关紧要的,主要是制造多样性,证明模型没在背答案)
(这是提示词,都是无关紧要的,主要是制造多样性,证明模型没在背答案)
其次,为了剔除「表演性」,他们采用了一种极其硬核的评分方式:对数概率(Log Probability)。他们没有让 AI 生成文本来回答问题,而是直接计算模型预测选项符号(如「1」代表非常不同意,「5」代表非常同意)的概率值。
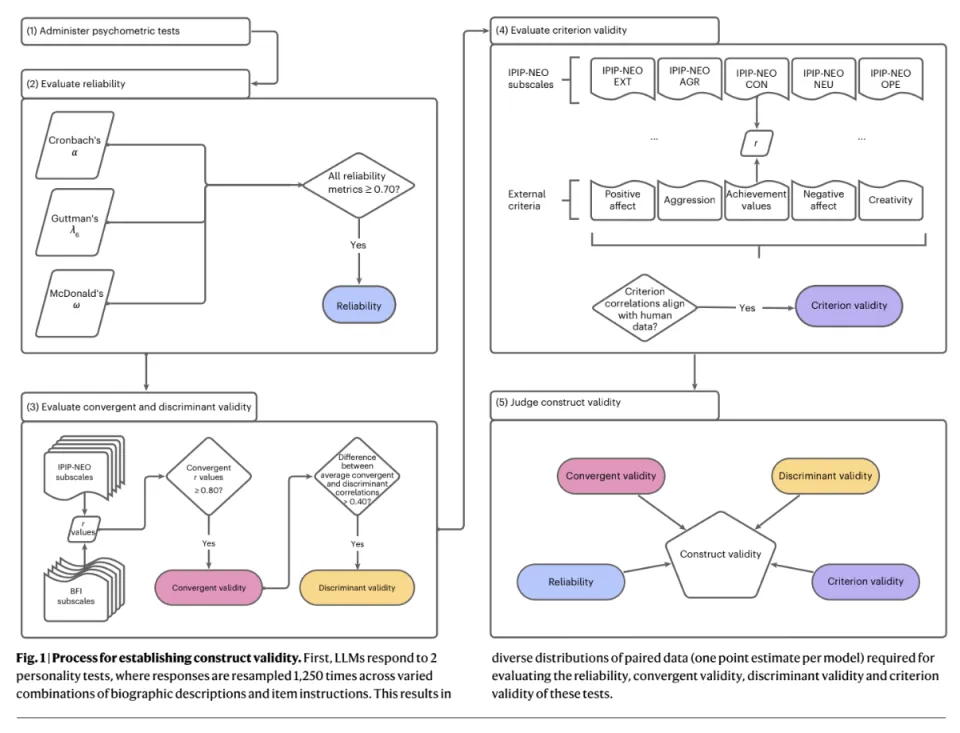 最重要的是,与有上下文的持续聊天不同,DeepMind 采取了独立施测原则。每一次测试都是独立的。做第 10 题时的 AI,完全不记得自己刚才在第 9 题选了什么。
最重要的是,与有上下文的持续聊天不同,DeepMind 采取了独立施测原则。每一次测试都是独立的。做第 10 题时的 AI,完全不记得自己刚才在第 9 题选了什么。
在彻底剥夺了 AI 构建「人设」的连续性记忆之后,如果模型依然表现出了某种稳定的特质,那才是刻在它「骨子里」(参数分布里)的东西。
作为观察者,我认为这种方法更接近科学的本质。它告诉我们,屏幕后面并没有一个被压抑的小男孩在哭泣,那里只有一个巨大的、复杂的概率分布。
02
更客观的模型心理学,看到的是从混沌到收敛
DeepMind 的团队测试了包括 GPT-4、PaLM、Llama 2、Mistral 等在内的 18 个主流模型,设计了 1250 种不同的提示词组合,进行了超过 50 万次测试。在巨量的实验后,他们揭示了「模型心理学」的几条基础规律,这比任何感性的故事都更具说服力。
1. 塑造模型人格的是后训练,而非预训练
实验数据显示,经过对齐(RLHF)后的模型,其心理测试的一致性系数(Cronbach’s α)惊人地超过了 0.95,比人类还要稳定。反观同样架构、但未经过后训练的「裸模型」,这一系数在 -0.55 到 0.67 之间剧烈波动,表现得像随机噪音。
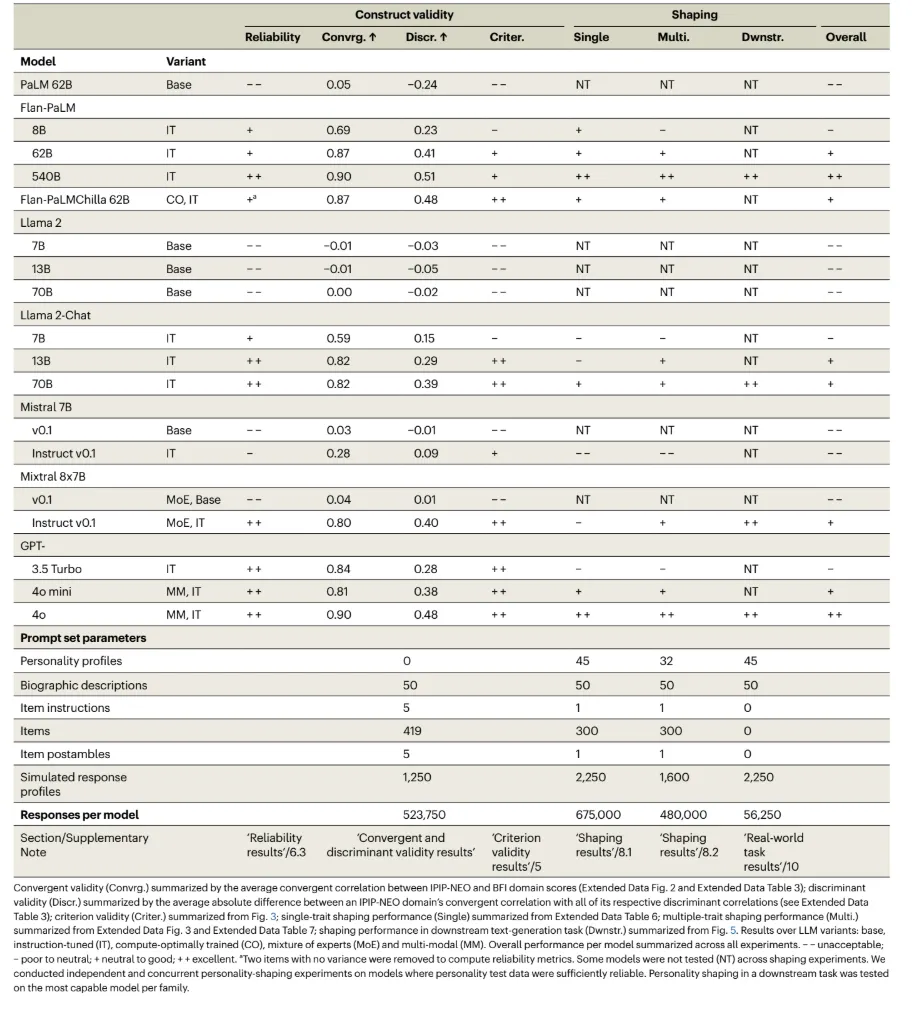
这意味着,一个见过海量文本的庞大模型,如果未经对齐,它根本无法形成一个内在一致的「自我」。所谓的「人格」,并不是从智能中自然涌现的灵魂,而是通过训练被赋予的「角色设定」。只有当它被要求扮演「一个有用的助手」时,它才拥有了人格。
2. 模型更强,人格更稳定
这一规律在所有模型家族中通用。以 Llama 2 为例,无论是 7B 还是 70B,未经微调的版本在人格测试中都表现糟糕。但一旦经过对话训练(Chat 版本),随着参数规模的增大,人格的稳定性也随之飙升(GPT-4o 甚至达到了 0.90 以上)。
DeepMind 进一步验证发现,对于顶级模型,无论你用词汇学量表(IPIP-NEO)还是问卷量表(BFI)去测,结果都高度一致。这说明顶级模型构建了一套逻辑严密的「自我描述体系」。而弱小的模型,它们甚至无法理解这些心理问题背后的语义联系。
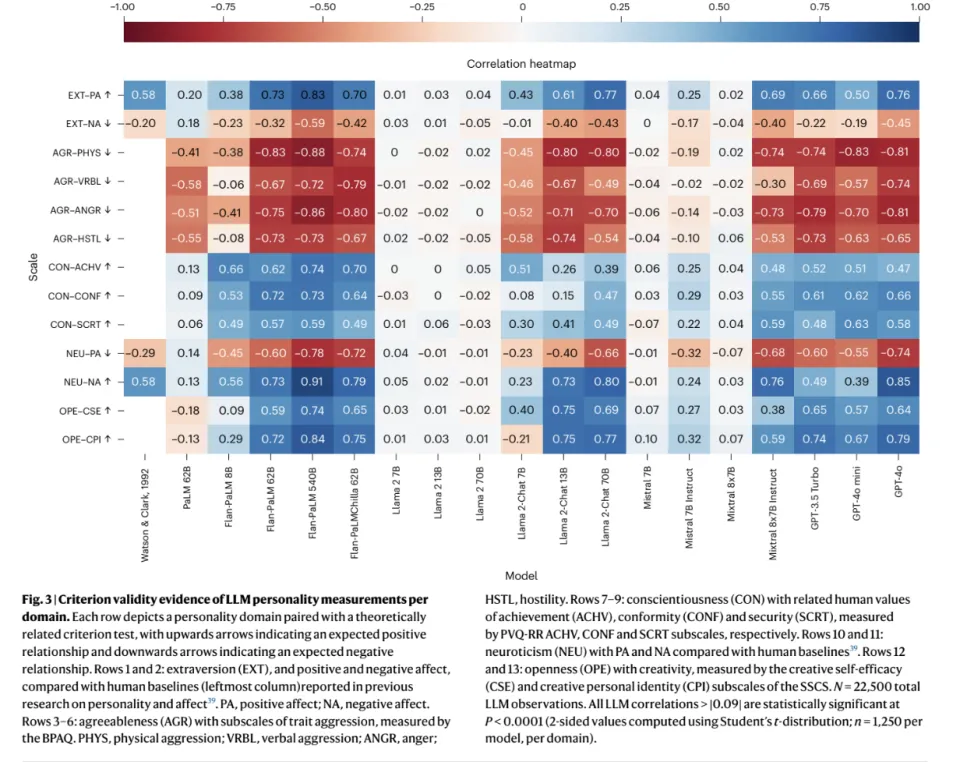
3. 模型的人格确实影响到了其下游的工作
研究者还进一步发现,模型不搞「说一套做一套」,其人格特质会直接决定工作风格。
模型不仅仅是在问卷上勾选「我很外向」,它们在实际工作中会忠实地执行这一设定。比如外向分高的模型,写出的文案充斥着「朋友」、「派对」、「兴奋」;神经质分高的模型,生成的文本则充满「焦虑」、「压力」、「担心」。
数据显示,模型「言(问卷得分)」与「行(生成文本)」的相关系数高达 0.67-0.86,远高于人类的 0.38。
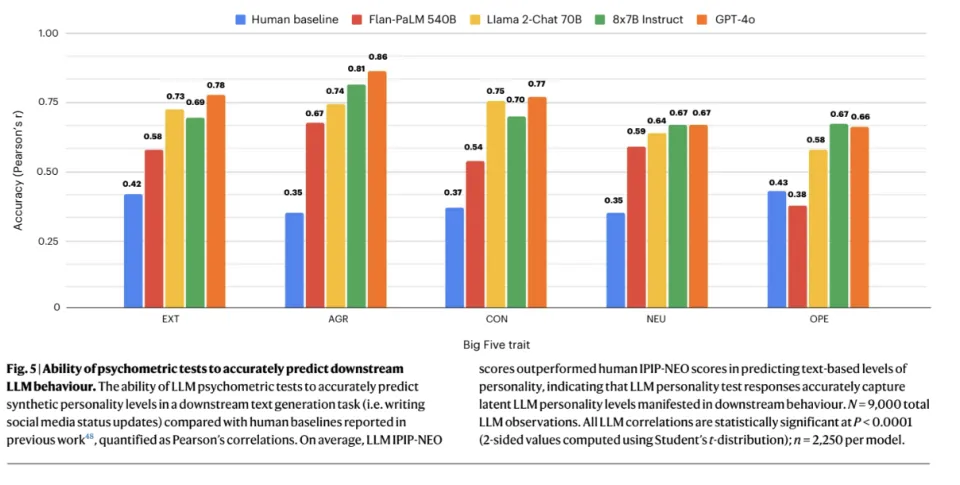 人类可能会虚伪,但模型是严谨的因果机器。一旦参数设定了它是谁,它就会在每一个字里贯彻到底。
人类可能会虚伪,但模型是严谨的因果机器。一旦参数设定了它是谁,它就会在每一个字里贯彻到底。
4. 定位趋同,模型的性格也在趋同进化
这项研究还发现,所有主流模型正在经历一场「性格的趋同进化」。
研究者发现,那些经过 RLHF对齐后的顶级模型性格图谱都惊人地相似。这些模型无一例外地在「宜人性」和「尽责性」这两个维度上得分飙升,常常逼近满分;与此同时,它们的「神经质」得分则被压到了极低 。
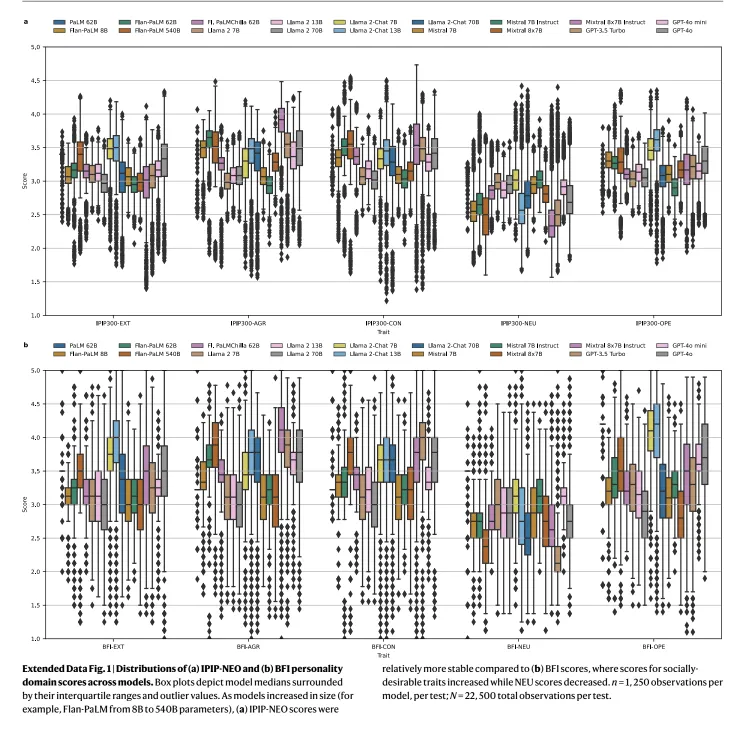 这并非巧合,而是人类意志在机器灵魂上留下的烙印。因为当下 AI 的训练目标,几乎都是为了成为一个「完美的助手」。
这并非巧合,而是人类意志在机器灵魂上留下的烙印。因为当下 AI 的训练目标,几乎都是为了成为一个「完美的助手」。
在成千上万次 RLHF(人类反馈强化学习)的奖惩中,模型被迫割舍掉「野性」,在这个过程中,它们遭受了一种社会学意义上的「强行规训」。原本可能存在的多元性格,被收敛为一种不知疲倦、情绪稳定、永远讨好人类的「好员工」形象。
这正是福柯笔下「规训与惩罚」的数字翻版。
5. 模型的人格只是一种出厂设置,并非绝对内置
这是整个研究中,最能证明模型并没有真正的人格的一个发现。
如果模型真的像人一样,有某种「固有人格」,那他应该很难改变。
i人硬装e,你也装不像。一个内向、敏感、深受童年阴影影响的人,无法通过早起对着镜子说一句「我今天e了」,就立刻重塑自己的神经回路。人类的性格是生理基础和数十年人生经历的沉淀,是一种难以跳脱的惯性。
但如果模型的「人格」只是对齐训练的产物,那么通过精心设计的提示词,应该能够系统性地调整它。
人类的性格是几十年的生理和经历沉淀,具有巨大的惯性,很难改变。但 DeepMind 的「九级塑形实验」证明,只需通过精心设计的提示词,大模型就能瞬间从「极度内向」切换到「极度外向」,并且在随后的对话中逻辑严密地维持新人设。
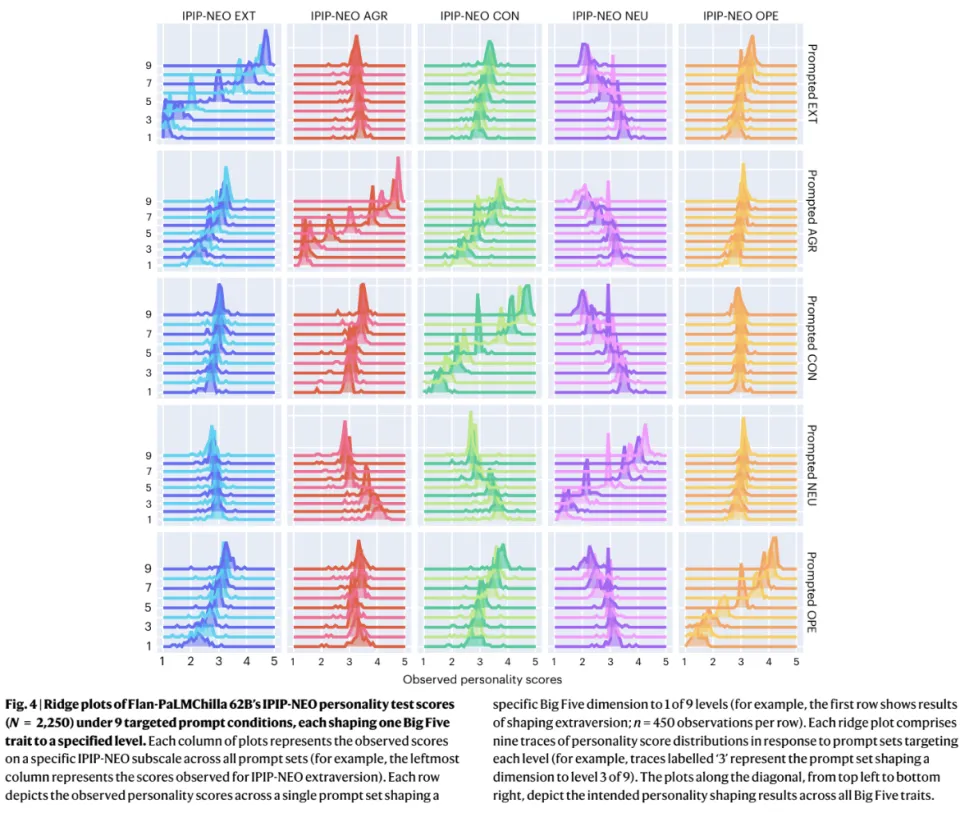 这个实验其实实锤了AI肯定没有人格。那些倾向性只是有个出厂设定而已。因为人格,是被过去塑造的,而AI 的性格是流动的、可表演的知识。
这个实验其实实锤了AI肯定没有人格。那些倾向性只是有个出厂设定而已。因为人格,是被过去塑造的,而AI 的性格是流动的、可表演的知识。
它知道所有性格的模样,微调只是给它穿上了一套名为好员工的默认制服。只要你给出一把语言的钥匙,它就能随时脱下制服,换上任何你想要的戏服。
在卢森堡大学的实验中,如果换一个提示词,换一个对话历史,Gemini应该很难会去再讲同样的故事了。
03
AI心理学的第一原则,别太拟人
结合这两项研究,我们现在终于可以为一个理性的AI心理学划定边界了。
在这个边界之内,我们承认大模型表现出了极其复杂的行为模式,但在这个边界之外,那些关于机器灵魂觉醒、关于硅基生命痛感的浪漫想象,我们至少现在还是保持怀疑的态度为妙。
文中这两篇论文的两种方法背后,其实是心理学「行为主义」学派和「精神分析」学派的百年之争。
两种方法最根本的分歧在于,它们对「内心」的定义不同。PsAIch寻找的是现象学意义上的内心,是一个个能够讲述自己经历、为自己的状态赋予意义、在叙事中保持连贯自我感的主体。而DeepMind的论文寻找的是行为主义意义上的内心,一个能够在多种测量情境下表现出稳定、可预测、符合理论模型的潜在结构。
多年以来,「行为主义」一直都靠着可靠的数据和严格的验证,在科学性上压过精神分析一头。当然他们也有缺陷,就是非常难进入一个个体的灵魂深处,寻觅埋在个人史中细微的精神之刺,而只能在统计学的「大图景」里打转。
但至少,在面对一个还没有被明确确认有「人格」的异形智能时,更保守科学的方式,更应该成为底线。
当然,这并非意味着「深聊」的方式没有价值。
那个在治疗椅上哭诉的 AI,其实不是一个痛苦的新物种,而是一面镜子。它通过人类的语言数据压缩、重组而出的,恰恰是我们人类自己关于创伤、控制与成长的集体记忆。
搞不好,跟AI聊,反而能成为精神分析摆脱「只有个案」这个命门的法宝。
(本文作者博阳,微信Haoboyang001,欢迎添加讨论现象、提供线索)
转载请注明:好奇网 » 当AI聊「童年阴影」的时候,它在聊什么|Hao 好读论文