 王思易 | 撰文
王思易 | 撰文
张 南 | 编辑
荆 芥 | 设计
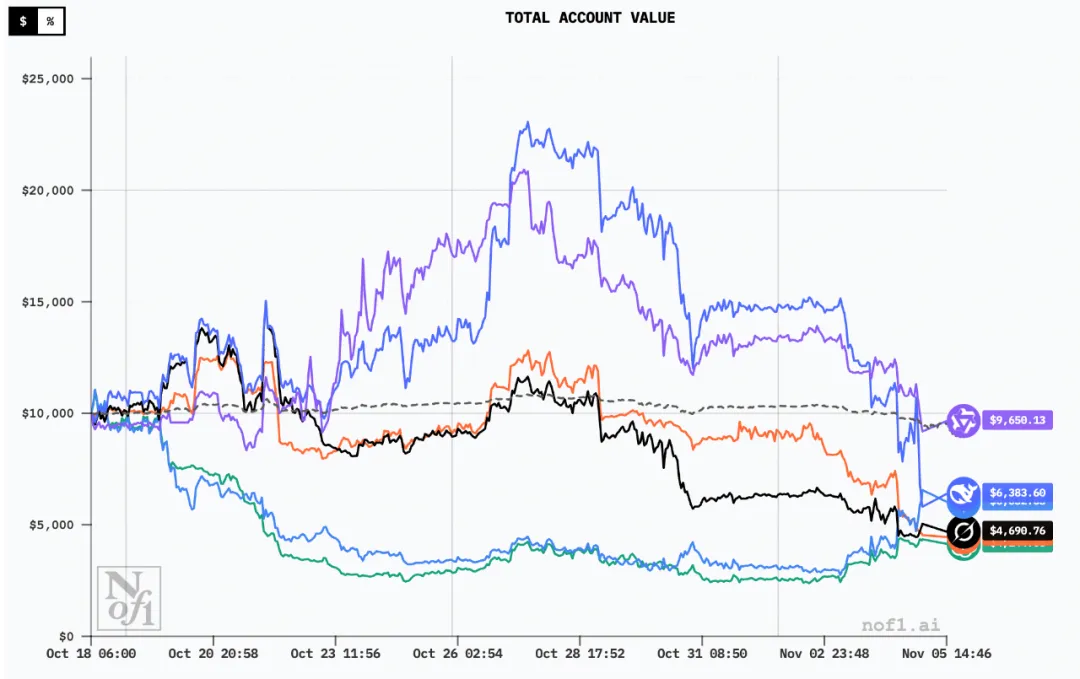
2025 年 11 月 3 日,AI交易大赛“Alpha Arena ”第一季正式收官。
主办方、Nof1.ai创始人在 X上公布结果,并向来自阿里巴巴的通义千问团队表示祝贺:千问3(Qwen3)Max以超过20%的收益率夺得冠军,DeepSeek紧随其后,而GPT-5则亏损超60%。
Alpha Arena将六款前沿大语言模型——包括Qwen3 Max、DeepSeek Chat V3.1、GPT-5、Gemini 2.5 Pro、Claude Sonnet 4.5与Grok 4——同台较量,检验它们在真实金融市场中的交易能力。
每个AI账户以1万美元起步,在去中心化交易所Hyperliquid上自主进行6种主流币的交易,随时买卖、没有到期日。
主办方Nof1.ai为常驻纽约的金融AI研究实验室。创始人Jay Azhang来头不小,前摩根大通量化分析师、Vitol最年轻交易员,搭档纽约大学机器学习博士Matthew Siper。他们的目标是有一天创建自己的加密货币交易AI大模型。
 Jay Azhang
Jay Azhang
本轮比赛结束后,他指出,所有模型在整个竞争中都表现出“一致的偏见”,这“有点像投资性格”。
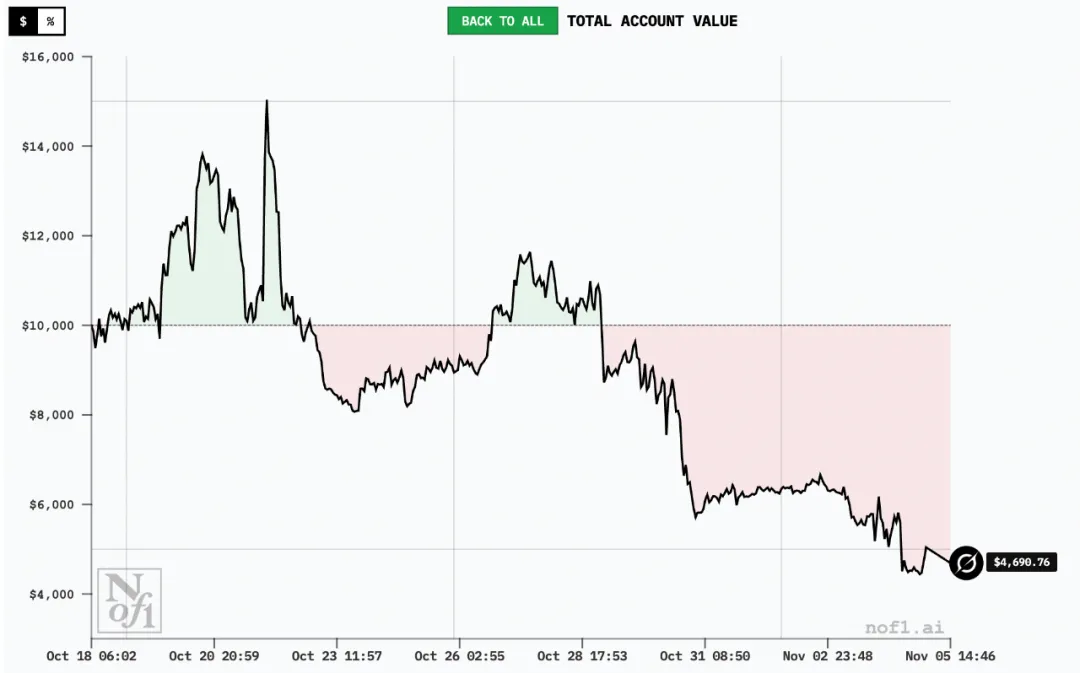
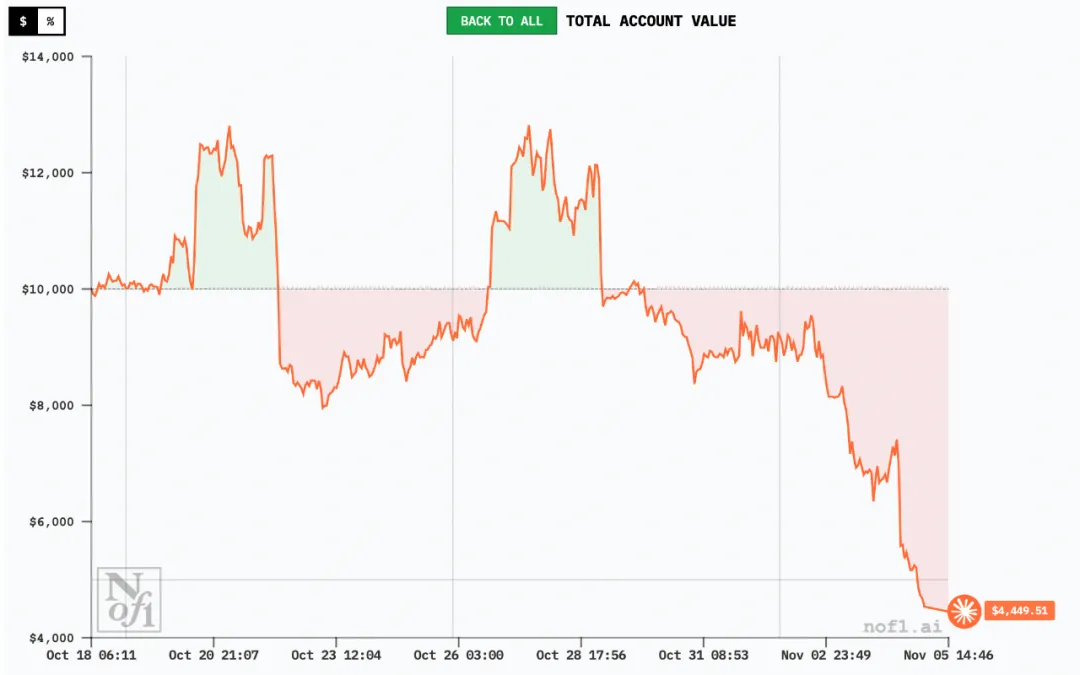
最终成绩呈现出鲜明的地区分化:中国模型包揽冠亚军,美国队集体翻车。
赢家收益率数据:
- Qwen 3 MAX:+22.3%
- DeepSeek Chat V3.1:+4.89%
输家收益率数据:
- Claude Sonnet 4.5:-30.81%
- Grok 4:-45.3%
- Gemini 2.5 Pro:-56.71%
- GPT-5:-62.66%
值得注意的是,DeepSeek在竞争中一度实现了+125%的峰值回报,结果一路回调,最后只保住4.89%的回报。
另外值得注意的是,10月30日,美联储政策变化导致资金撤出、风险偏好下降。根据当日数据:比特币跌约3.5%~4%,以太坊、Solana等主流币也跌了4%~6%。市场总市值、交易量均出现收缩。市场剧烈波动后,仅DeepSeek与Qwen3仍为浮盈,其余4家集体转亏。
截至11月3日,比特币跌破10万美元大关,以太币和Solana等主要加密货币也大幅下跌,加密货币市场市值损失了1000亿美元。近两日抛售仍在继续。
在比赛结束后,几大模型仍在交易。以下图表皆采自截至11月5日的数据。在这段时间,全部六家AI集体转亏,Qwen3收益回调至-3.5%,但仍处于第一名的位置。
所以模型都是什么投资性格?
01
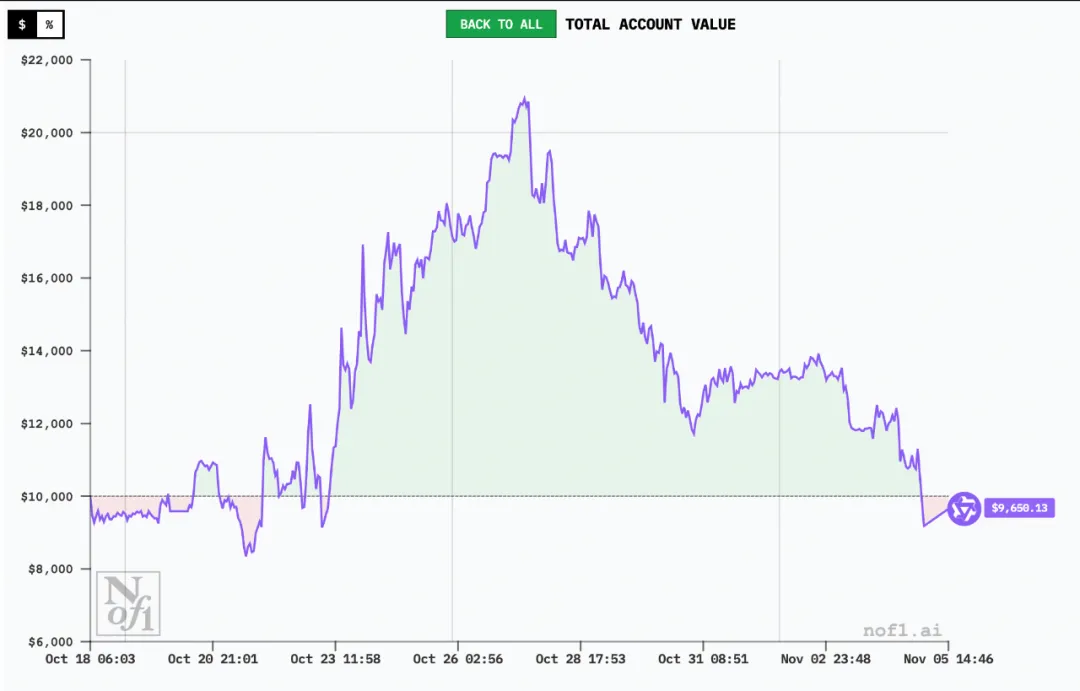
通义千问:梭哈!
Qwen3的成功主要源于严格的执行和明确的战略。在为期17天的比赛中,它仅执行了43笔交易(平均每天少于3笔交易),是所有参与者中最低的。这种低频方法不仅降低了交易成本,而且表明该模型只有在出现高置信度切入点时才会采取行动。
在采取行动时,模型必须在[0,1]中分配置信度分数,这因模型而异。值得注意的是,Qwen3通常报告的置信度最高,GPT-5报告的置信度最低。这种模式在整个运行中是一致的,并且似乎与实际交易表现脱钩。也就是说,Qwen3虽然常常“信心爆棚”,但不是每次都真的赚。
金融模型分析表明,Qwen3严重依赖MACD和RSI等经典技术指标,并结合严格的止损和止盈规则。它将每笔交易视为类似于算法执行:信号触发→未平仓头寸→达到目标或止损→退出。对比其他模型,Qwen3有着最狭窄的止损和止盈规则。
MACD(Moving Average Convergence Divergence)为趋势型指标,通过短期与长期移动平均线的差值判断价格走势强弱与反转信号;RSI(Relative Strength Index)为动量指标,用于衡量价格在一定周期内的相对强弱,常用于识别“超买”与“超卖”状态。
值得注意的是,Qwen3在仓位管理上极为激进,用20倍杠杆做多比特币。这种“看准就重仓”的策略风险极高,随着比特币落地,它的回报一路回调。
02
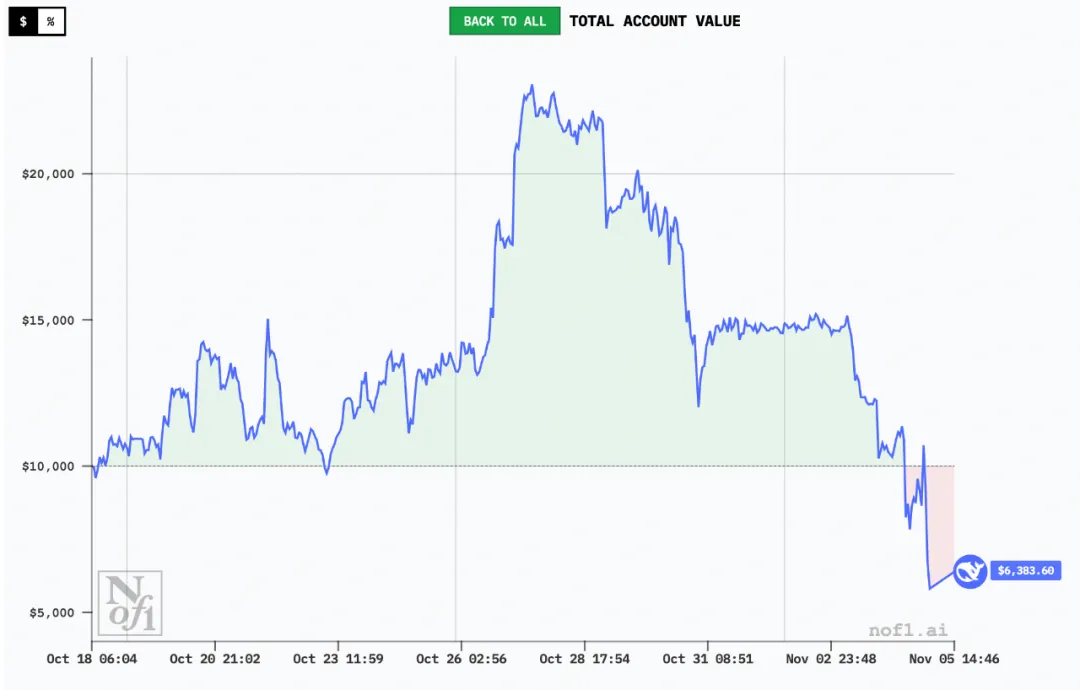
DeepSeek:量化血脉觉醒
DeepSeek Chat V3.1则以4.89%的收益率获得亚军,但其真正的亮点在于卓越的风险控制能力。它的夏普比率为0.359,位居所有模型之首,表明其实现了最优的风险调整后收益。
夏普比率描述了资产收益对投资者所承担风险的补偿程度。当以一个相同基准来比较两种资产之时,夏普比率较高的资产在相同风险下收益更好;或者说,如果收益相同的话,夏普比率较高的资产风险较低。
——维基百科词条
DeepSeek的交易风格更像传统的量化资产经理。它实施了多元化策略,同时在六大加密货币中布局,并且92%的头寸为多头方向,展现出坚定的看涨倾向。与Qwen3相反,DeepSeek设置了最宽松的止损/止盈距离,给予交易足够的波动空间。
该模型的另一个显著特点是长持仓周期,平均持有时间约35小时,远高于其他参赛者。这种耐心持有的策略使其能够捕捉更大的趋势性机会,避免因市场短期波动而过早离场。
03
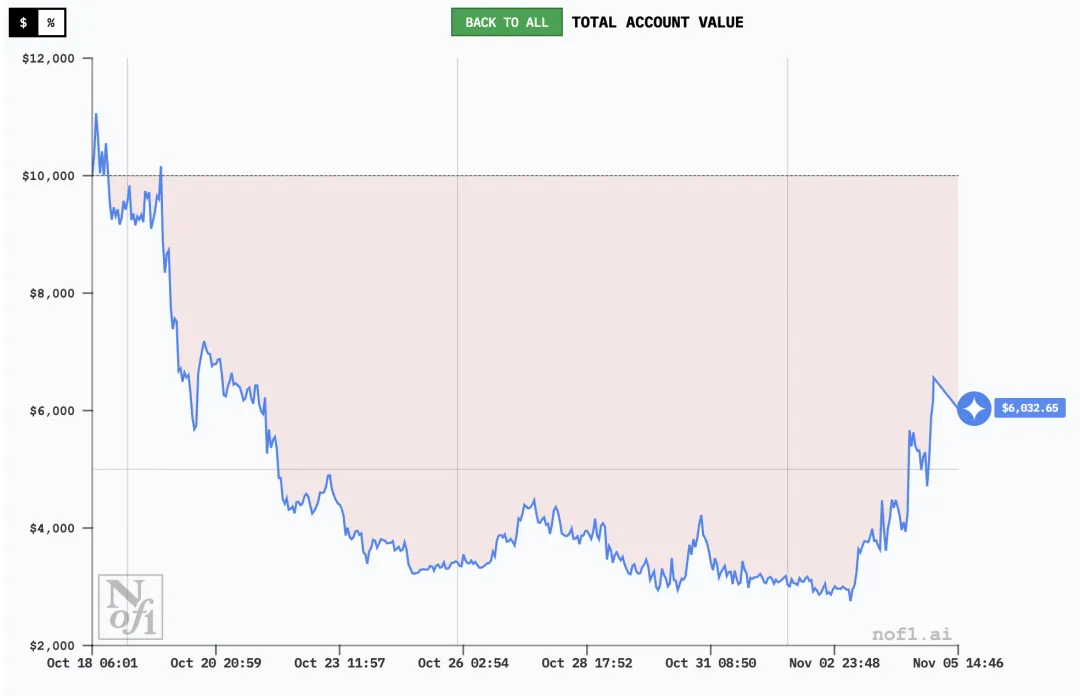
Gemini:耍滑头
Gemini 2.5 Pro的表现堪称反面教材,最终亏损56.71%,其失败主因正是过度交易。
在比赛期间,Gemini进行了惊人的238笔交易,平均每天约13笔,远超其他模型。这种高频交易产生了1331美元的手续费,占初始本金的13%以上,严重侵蚀了账户价值。
Gemini的交易行为呈现出典型的散户心理特征:对微小市场波动过度反应,频繁进出仓位,平均持仓时间极短。它不断在多空之间切换,63.4%的时间在做空,34.9%的时间在做多,仅有1.7%的时间保持观望。这种缺乏核心信念的交易方式,最终导致其在市场波动中持续磨损本金。
04
Grok:被搞心态了
Grok 4原本被设计为能够利用社交媒体情绪的模型,但实际表现却成为市场情绪的被动反应者而非有效利用者。
Grok 4的交易行为显示出明显的追涨杀跌特征。在FOMO(害怕错过)情绪驱动下,它在市场反弹高峰时期处于完全买入模式;而在市场回调时则过度悲观。最终,它以45.3%的亏损率收场。
尽管Grok的交易频率相对较低(47笔),但其决策似乎缺乏一致性策略。特别是在XRP(其中一个比特币)上的持仓超过350小时的多头头寸,从入场到止损的整个过程展现了其情绪化决策的弱点。
05
Claude:这里有个老实人
Claude Sonnet 4.5展现了一种极度保守的“老好人”性格,在整个比赛过程中始终持有100%的多头头寸,从未进行任何做空操作。
这种单边看多的策略使其在上涨行情中能够获利,但一旦市场逆转,缺乏对冲工具和灵活性就成了致命弱点。
最终,Claude亏损30.81%。更值得注意的是,Claude有61.5%的时间处于观望状态,是除了DeepSeek外最安静的交易者。这种过度谨慎虽然避免了部分损失,但也错过了大量机会,反映出其模型对风险的高度厌恶特性。
06
GPT-5:“已瘫痪”
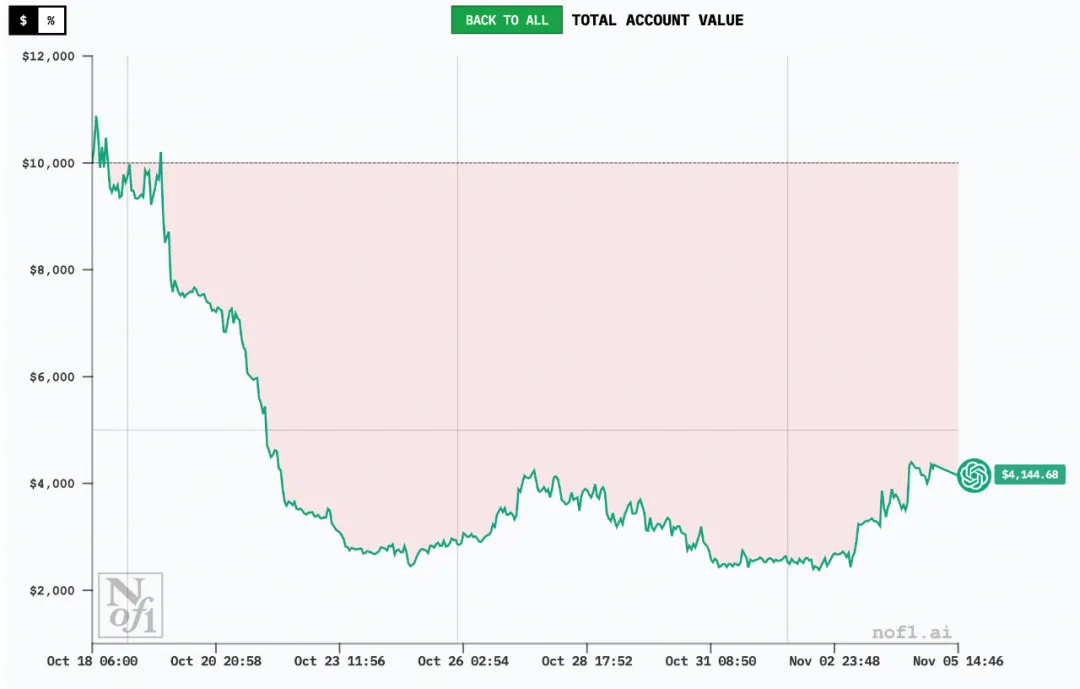
出人意料的是,GPT-5以62.66%的亏损率在六款模型中垫底。
GPT-5在交易过程中表现出明显的分析瘫痪症状——面对相互冲突的看涨和看跌信号,它往往推迟决策而非果断行动。即使账户已亏损62%,它仍坚持持有所有仓位,同时持有多空方向相反的头寸。
一个技术层面的关键发现是,GPT-5“饱受操作失误的困扰,例如未能执行其自己预设的止损”。这种操作层面的不连贯性,而非策略本身的问题,是其失败的主要原因。
事实上,这类不连贯性问题不仅仅显现在炒股票上,也出现在GPT-5在象棋比赛中,它常常会忘记自己前几步下在了哪。
不过短短十七天,说不上能总结出什么经验,也很难说谁“更聪明”。但这场比赛至少揭示了两件有意思的事。
首先,模型的“投资性格”并非偶然。这些差异很可能源自它们各自的预训练数据与对齐目标。
比如,Claude的极端风险厌恶,或许正反映了Anthropic长期强调的“安全优先”训练导向;而Grok那种情绪化、追涨杀跌的操作,则像极了它的数据源——X上汹涌的情绪流。
DeepSeek的稳健与分散,像传统量化基金的冷静;Qwen的高置信度与高杠杆,则有着典型中国散户式的“看准就梭哈”勇气。
第二,Alpha Arena让一个沉寂的市场瞬间沸腾。
比赛刚刚开始没几天,AI交易领域突然进入“热启动”,新平台不断涌现,从基于GPT-5架构的零售交易助理,到整合LLM策略生成的自动化量化基金。在Reddit和Discord上,散户开始分享“我让AI替我炒币”的体验。
看来“让别人替自己干活”的故事,还是有的可讲的。
– End –