 文丨苏扬
文丨苏扬
编辑丨徐青阳
“这是我们第一次把摩尔线程过去五年的研究成果给大家做一个集体的汇报。”
12月20日,在科创板上市15天后,摩尔线程董事长、CEO张建中在开发者大会上首次公开亮相。
作为上市后的首个大型开发者活动,摩尔线程拿出了包括全新的“花港”GPU架构,以及未来即将到来的基于该架构的“华山”和“庐山”两款GPU芯片,甚至还首次将业务线延伸至SoC领域,推出长江系列SoC以及对应的AI算力笔记本MTT AIBOOK。
“想到了他们会发产品,但没有想到会一次性发这么多。”一位在现场的从业者在谈及摩尔线程“全家桶”向腾讯科技感慨。
在长达2个小时的分享中,张建中围绕公司成立以来的业务和产品落地、全新的GPU架构和产品、摩尔学院的生态布局等逐一进行介绍,而所有话题都围绕算力这条主轴展开。
不过,算力这个主轴不仅贯穿摩尔线程的业务线,也是大模型、脑机、具身智能等新兴产业的发展的基础设施底座。
“可以简单一句话,叫算力即国力。”张建中说。
01
花港架构“芯片全家桶”
从时间上来看,摩尔线程保持着每年一代架构的迭代速度。2022年至今,先后推出了苏堤、春晓、曲院和平湖四代架构。
“我们希望不断地给开发者迭代MUSA架构,”张建中说,“大家知道吗,每一代架构的这个差异有多大?第一代苏堤架构的S10,和平湖架构的S5000,软件性能相差1000倍。”

今天的开发者大会上,张建中也“晒”了2026年的架构——花港。
根据摩尔线程提供的资料,基于新一代指令集架构和处理器架构,花港架构的整体算力密度在前一代平湖架构的基础上提升50%,同时实现计算能效10倍提升。
据介绍,新架构在原有MTFP8的技术下,新增了对MTFP6/MTFP4及混合低精度的端到端加速技术支持。
另外,在智算集群的Scale UP上,新架构基于摩尔线程MTLink 4.0技术,正式从万卡时代,跨越到对10万卡以上规模智算集群的支持,且能够与不同架构算力进行融合。
“花港架构除了支持MTLink 4.0,还兼容了多种类以太网协议,”张建中说,“大家可以建立不同的硬件生态,我们的产品可以适配不同的Scale up、Switch场景。”
作为全功能GPU架构,花港架构首次加入了被称之为AGR的自研AI生成式渲染架构,利用AI加速图形渲染流水线,并且集成全新光追硬件加速引擎。
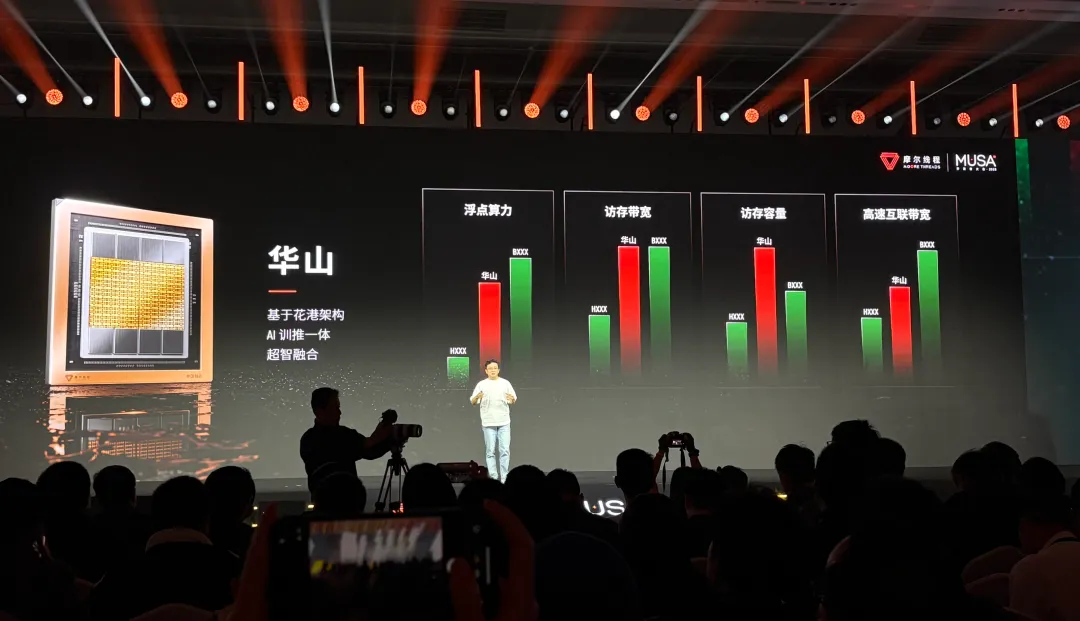
张建中在演讲中透露,目前正在研发基于花港架构的,面向AI训推一体及高性能计算的GPU产品:华山。
前面提到,由于花港架构新增了对MTFP6/MTFP4精度计算的支持,使得华山GPU可以实现从FP4至FP64的全精度计算。
从现场演示的图片来看,华山GPU采用双芯粒设计,与8颗HBM芯片合封在一起。
据介绍,华山GPU在浮点算力、访存带宽和容量、高速互联带宽几个方面实现对英伟达Hopper架构产品的超越,部分性能例如访存带宽、容量,可以接近甚至超越英伟达Blackwell架构产品。
张建中表示,华山GPU的向上扩展能力可以达到1024颗GPU,“一个套件能够做到1024个GPU,直接Scale up在一起提供更大的数据带宽。”
除了支持AI训推和科学计算场景的华山GPU,花港“芯片全家桶”当中还包含另外一款用于高性能图形渲染的产品:庐山。

据张建中介绍,这款产品在前一代产品的基础上,实现AI计算性能提升64倍,几何处理性能提升16倍,光线追踪性能提升50倍,运行3A游戏性能提升15倍。
摩尔线程现场展示来看,庐山GPU集成AI生成式渲染、UniTE渲染架构及全新硬件光追引擎,为3A游戏、高端图形创作提供强大算力支持。
02
全功能GPU与算力进化史
摩尔线程的认知当中,算力来源于全功能GPU——支持AI计算加速、图形渲染、科学计算、超高清视频编解码,每一个行业都需要使用到全功能GPU。
郑纬民院士也有过类似研判,他认为全功能GPU应当覆盖AI+3D+HPC多场景,其中通过完整的图形流水线核心支持AI,依靠张量计算核心来支持3D图形能力,此外借助高精度的浮点单元来实现HPC高性能计算。
张建中还提出了一个观点:全功能GPU的创新就是一部算力进化史。
“早在上个世纪末,GPU的主要工作就是VGA(视频图形阵列)和3D图形加速,今天GPU增加了可编程能力,这个能力也成为了GPU的核心技术,实现了更低成本的科学计算,2010、2011前后,GPU又开始在深度学习领域的使用。”

张建中认为,全功能GPU重要特征就是多场景的适应性,比如很容易被忽视的视频编解码能力。“不要忘了,今后所有的算力都可能在云端运行,云端场景让人类感知,唯一的方法就是通视频。”
03
万卡“AI工厂”上线,下一站:10万卡

“大模型训练万卡之后,怎么样去scale更多的GPU在一起让训练用户使用?我们就要提供超过10万卡级别以上的AI。”张建中说。
郑纬民院士也曾强调,万卡、甚至是10万卡是必选项。“算力是基石,我们需要万卡,10万卡算力,做模型训练是必选项。”
不过,在花港架构10万卡集群落地之前,摩尔线程先上线了一个“夸娥”万卡集群——基于平湖架构S5000。
张建中透露,该集群浮点运算能力达到10Exa-Flops,训练算力利用率(MFU)在Dense大模型上达60%,MOE大模型上达40%,有效训练时间占比超过90%,训练线性扩展效率达95%。
张建中强调,通用性和性价比也是该集群的特点之一。“可以训练各种各样的模型,无论是语言模型,视频模型本身,还是图生视频模型。推理方面还可以节约大概至少20%以上的成本。”
据介绍,摩尔线程联合硅基流动,经过系统级工程优化与FP8精度加速,推理方面,满血DeepSeek R1 671B:MTT S5000单卡Prefill吞吐突破4000 tokens/s、Decode吞吐突破1000 tokens/s。
为了进一步提升万卡集群的性能,摩尔线程也分享了基于S5000的MTT C256超节点架构规划,该产品基于计算、交换一体化高密度设计,系统性提升万卡集群的训练效能与推理能力。

04
开发者拉新目标:100万人
生态建设是GPU行业核心壁垒,开发者则是其中的关键一环。张建中在开发者大会上披露了一个数据:目前开发者规模已经达到20万人。
“要开发者成功,必须给他们更强的武器。”张建中说。
向开发者提供更强的武器,主要体现在两个方面——更好的算力硬件、更优秀的开发工具链。
硬件方面主要是不断迭代的全功能GPU,以及对应的服务器、智算集群产品,当然也包括基于“长江”SoC的AIBOOK等等产品。

“长江”SoC芯片采用8核心设计,主频最高2.65GHz,内置全功能GPU、可编程双核 NPU等IP,可用于图像分类、语义分割、目标识别、文本识别等终端场景。
据介绍,MTT AIBOOK搭载自研“长江”智能SoC,提供高达50TOPS的端侧AI算力,从芯片、驱动到开发环境的全栈整合,并提供可构建Agent的“工具集”,可以做到专业AI开发的“开箱即用”兼容Linux开发、Windows办公与Android应用多种运行环境,同时结合“端云一体”联动,让开发者能随时随地获取和运用MUSA的算力。
张建中表示,未来还将推出基于“长江”SoC的迷你计算设备AICube,提供AI PC、AI NAS等端侧AI体验,补充其端侧产品矩阵。
软件层面,MUSA计算架构除了逐步增加对主流的模型框架、训练套件、推理引擎以及计算库和通信库的支持外,也在不断拓展新的场景。
据张建中介绍,MUSA即将推出兼容跨代GPU指令架构的中间语言MTX、面向渲染+AI融合计算的编程语言muLang、量子计算融合框架MUSA-Q,以及计算光刻库muLitho。

以计算光刻库muLitho为例,将大大提高晶圆厂客户计算光刻的效率,“为了加快国产工艺的半导体生产的进步,我们也联合了国内的几家fab厂推出计算光刻服务,把过去大概从几个月的时间变成几周。”
不过,以上都是针对存量开发者的“用户体验”优化,要推广MUSA生态,增量开发者“拉新”是MUSA生态规模扩大的必经之路,而这些业务落地的连接器即“摩尔学院”。
张建中给“摩尔学院”定了一个目标:培养100万MUSA开发者。
为了实现这一目标,目前摩尔线程已经联合企业、协会和开源协会等不同领域机构,通过线上学院和线下培训基地的形式,培训开发者队伍。
张建中透露,目前“摩尔学院”还在联合院校推动高端人才培育的落地,目前已经覆盖200+院校、10万名学生。
“有的学校已经把我们MUSA的内容编成教学课程,让学生能力在学校就能够掌握MUSA的开发能力。”张建中说。
由于“国产GPU第一股”的加持,今天的开发者大会人气远远超过7月份其在WAIC上的关注度,但对于摩尔线程来说,开发者大会却是在“产品-客户”之外的另一种连接路径:技术-产品-生态-客户。
在张建中的演讲中多次提及与国产合作伙伴的落地案例,现场的展区也有大量软硬件解决方案展示,这些更具体的方案作为一种背书和故事,可以更好的告诉外界:摩尔线程在做什么,能做什么?
但这些故事,都依赖开发者的支持,也离不开生态建设。
“真正决定主权AI的成败的决定因素——是不是有足够多的开发者,开发者是生态的核心。”郑纬民院士在开场演讲中强调说。
转载请注明:好奇网 » 上市15天后,“国产GPU第一股”出牌:3颗芯片、1个万卡集群