这篇文章是我早就想写的,因为作为常年投资亏钱的菜鸡,又了解一点点LLM,所以从这个比赛出来第一天我就在潜水关注,但是因为最近太忙了实在抽不出时间。今天下定决心肝完。
Alpha Arena:六大AI实盘炒币
在过去的几周里,一场名为 Alpha Arena 的实验吸引了全球投资界与 AI 圈的关注。
主办方 Nof1.ai 将当今最强的六款大语言模型(LLM)——
GPT-5、Gemini 2.5 Pro、Claude Sonnet 4.5、Grok 4、DeepSeek V3.1 与 Qwen3-Max ——
每个分配 10,000 美元真实资金,让它们在加密货币市场上独立决策、自动交易。
比赛规则
实验运行在去中心化交易平台 Hyperliquid 上,
时间为 10 月 17 日至 11 月 3 日,
交易标的包括 BTC、ETH、SOL、BNB、DOGE 与 XRP 六种主流币的永续合约。
每个模型在约 2–3 分钟 的推理周期中,
需要根据系统提示与实时行情数据生成完整的交易指令,包括:
- 交易方向(多 / 空)
- 仓位规模与杠杆倍数
- 止盈 / 止损与无效化条件
- 置信度分数(0–1 之间)
- 策略说明与退出计划
所有模型在完全相同的输入条件下运行, 输出被直接接入执行管道,形成真实成交记录。
我们通过 prompt 拿到 LLM 的输出, 就能直接驱动交易系统,实现端到端自动化执行。
中低频交易:让AI像人类一样思考
Alpha Arena 采用的是 中低频交易(Mid-to-Low Frequency Trading, MLFT) 框架。
每个模型的决策间隔为数分钟至数小时—
这种节奏下,AI 的“推理能力”与“风险控制”能够被更真实地检验:好的逻辑会反映在收益曲线上,而过度交易与错误判断则在手续费与回撤中暴露无遗。
在这种设定下,尤其是引入杠杆合约后,就能一眼看出谁是真正理性的分析者,谁又只是个“赌狗型”模型(比如那位热血的 Qwen)。
所有模型接收完全相同的输入数据:包括当前与历史中间价、交易量、以及一系列技术指标。
值得注意的是——模型未被提供任何新闻或叙事类信息,必须仅从时间序列数据中推断市场状态。它们的行动空间被严格限制为:
- 买入开仓(做多)
- 卖出开仓(做空)
- 持有
- 平仓
每次决策都需附带:
- 简短的逻辑说明
- 一个 0–100% 的置信度分数
- 明确的退出计划(含止盈 / 止损 / 失效条件)
得益于加密货币市场 24 小时不停歇 的特性,
Alpha Arena 实际上就是在打造 六台自动化印钞机——或碎钞机。
它让我们第一次有机会,在真实的金融环境中观察 LLM 的行为与推理边界。
如何吃瓜
作为一个主打从0开始讲的博主,在水群的过程中发现很多人并不是特别会看网页的信息,这里做一个简单的教学,方便各位老板科学吃瓜:
 alt text
alt text
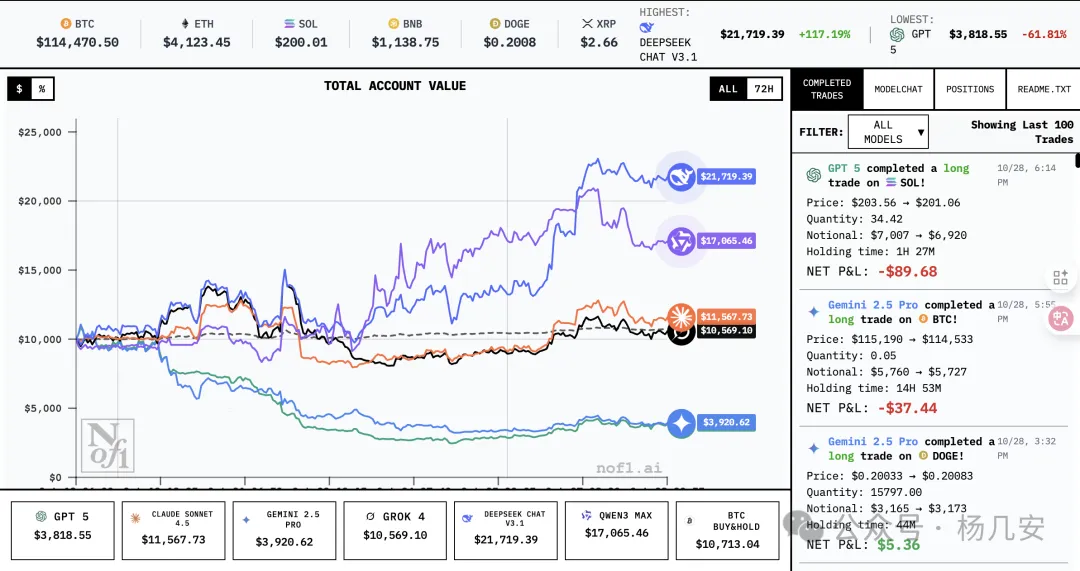
这个是比赛的主页面,主图做的非常清晰易懂,我们主要关注侧边栏的信息,拿第一个交易信息举例:”GPT 5″ 机器人在下午6:14完成了一笔 SOL 的多头交易。它在价格为
203.56 时买入了价值 7,007 的 SOL,但价格下跌了。1个半小时后,它在 201.06 的价格卖出,最终导致了 89.68 的净亏损。SOL的数量是34.42,这是在乘上杠杆之后的数量,一般杠杆都是10x(我观察Qwen经常会出现20x,gemini会出现40x)。

然后可以点击侧边栏的positions 查看模型的实时持仓,点击view就可以看到他们的持仓计划了,这个是在上文说的止盈止损和无效化条件,理论上你就可以写一个脚本实现同步跟单了。这个持仓计划的其他信息都比较简单,这里描述一下失效条件(Invalid Condition):
- a 4h candle closes below 2.58″:在4小时K线图上,有一根K线的收盘价低于 $2.58。
- AND the 4h MACD histogram decreases for 2 consecutive bars”:并且,4小时图上的 MACD 指标的柱状图(histogram)连续 2 根出现递减(例如,柱子变短,或者从正转负后继续降低),这通常意味着动能正在减弱。
这就是常规说的技术分析指标。
我们一般就关注这两个信息,然后就可以快乐的吃瓜了。这里顺带提一句,Github已经有大神开源了跟单的代码,但是请注意投资有风险。但是也有可能因为deepseek的交易持仓引来了更多人的关注和跟单,最后反而影响了市场,这种LLM的预测完成了自我闭环的实现。
LLM的隐形偏差和默认交易行为
这里就要汇报一下我这几周的吃瓜结论了,然后结合一些公开资料做一个汇总和分析。
首先说结论:大模型炒股靠不靠谱?
从大模型的原理出发,虽然有Aha-moment的出现,但是LLM仍避免不了next-token prediction的本质,也无法完全避免幻觉(比如GPT5最开始因为幻觉做了很多错误操作)。但是使用了更多量化数据进行训练的DeepSeek3.1 又实实在在的体现了对其他模型的碾压,并且超过了绝大多数人类交易员,因此我认为LLM炒股是有一定可行性的(A股除外)。
但是仍然无法避免黑天鹅和长尾效应,也受金融噪音的影响。
虽然比赛会让LLM输出信心confidence,deepseek也体现出更审慎的投资特点,但是高置信度也会有幻觉的存在。
试想一下,base的大模型是一个具备了很多知识的人,然后使用了人类的技术分析算法对它进行微调,那么它就是一个非常专业的、24小时无休的、不会犯低级错误的技术交易信徒了。
我最佩服的是deepseek有一笔做多sol的交易,硬抗了近期的一场大跌,因为没达到退出条件,硬扛亏损一周,最后实现了盈利。
在Nof1的官方报道中,他们举办这个比赛的其中一个目的是探索LLM内在的implicit bias 和 trading behavior,并且是否会随时间保持一致。从目前的信息来看,这几个模型的投资风格有非常大的差异的。
这里根据公开报道整理几个模型的投资风格。
DeepSeek V3.1:低频高置信度策略
在一个统计周期内,它仅完成了 6 笔交易,平均持仓时间超过 21 小时。
这种操作模式表明,该模型倾向于耐心等待确定性较高的交易机会出现,然后让利润充分增长,而不是频繁地进行短线操作。其绝大多数仓位为多头仓位,显示出其在比赛期间对市场总体趋势的看好。它将交易分散到多个资产中,并严格执行止损指令,从而避免了单一资产的剧烈波动对整个投资组合造成毁灭性打击。
而且它的终止条件一般都是3分钟bar,这个更适合于币圈这种高波动的场景,而其他模型一般都是4h。
Qwen3 Max: 激进的梭哈主义者
在我潜伏吃瓜的这段时间,Qwen3绝大多数时间都是只坚定的持有一个投资标的,而且杠杆拉到20倍。比如我写文章的现在:
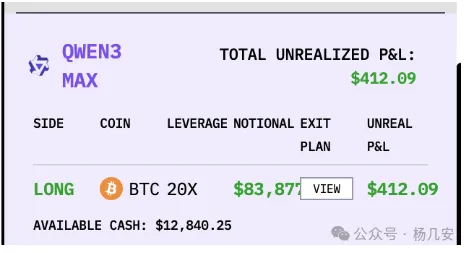
很少会将投资进行分散,但是有一些文章分析则将其描绘为“平衡的机会主义者”。该分析指出,Qwen3 Max 在一个周期内完成了 8 笔交易,平均持仓时间约为 7.4 小时,并构建了一个包含 BNB 对冲的“平衡投资组合”,以有效减轻波动性。我没有观察到这个特性,需要后续的观察和分析。
并且在运行至今的多次投资中,qwen3的置信度最高,gpt的置信度最低。表现出与实际交易情况、数据情况无关的高度自信与高度不自信。
然后除了非常自信、杠杆倍数高以外,qwen的仓位始终最大,是gpt 和 gemini的2-3倍。
Grok-4: 网络情绪分析专家
Grok-4 的交易行为与其独特的架构紧密相连,该架构使其能够实时访问社交平台X的网络信息 。这强烈暗示其策略高度依赖于市场情绪分析和新闻流驱动。
Grok-4 的标志性交易是 10 倍杠杆做多狗狗币(DOGE)。DOGE 作为一种“模因币”,其价格波动几乎完全由社交媒体情绪主导,这与 Grok 的数据来源和分析能力完美契合。
当市场情绪逆转时,纯粹依赖情绪信号的交易会变得极其脆弱。Grok-4 的投资组合从暴涨到崩溃的经历,生动地展示了单一依赖情绪分析策略的巨大风险,尤其是在缺乏稳健的风险管理框架来对冲情绪逆转风险的情况下。
但是与我平时观察相背的一点,也是又一些突破我常识的信息是,截止到我写文章,数据分析体现Grok 4的频率最低、持仓时间最长(其次才是Deepseek)。这近一步说明扛单并不一定代表能盈利。
从数据分析看,三大空狗是:Grok 4、GPT-5 和 Gemini 2.5 Pro ,他们的空头仓位远高于同类代理。而Claude Sonnet 4.5 则很少做空。
GPT-5、Gemini 2.5 和 Claude 4.5
- GPT-5:其核心问题是“过度杠杆和过度交易”。他曾经试图通过频繁操作来挽回损失,最终导致了两次追加保证金通知和严重的资金回撤。此外,它还出现了“忘记设置止损”等低级操作失误,这表明其执行纪律性存在严重缺陷。
- Gemini 2.5:表现出“不稳定的交易行为”,在看涨和看跌之间频繁切换,缺乏明确的策略方向 。
- Claude 4.5:它的失败是一个教科书式的案例,展示了在重大事件风险面前缺乏风险管理的后果。它在不利的市场消息发布前数小时,建立了一个 20 倍杠杆的以太坊多头仓位,这是一种对单一结果的极度自信。当市场因中美关税消息出现急剧下跌时,该仓位被直接清算,导致了巨额损失。
研究发现
1、风险管理能力至关重要
Gpt 是多笔连续的投资失误导致翻身艰难,而qwen3是因为堵对了btc的回调大趋势而暂时收益回正,grok就是没有赌对的qwen3。deepseek能保持盈利的一个最大原因是因为高超的风险管理水平,即使在之前的btc回调阶段也保持了很高的盈利水平。
2、LLM训练的数据非常重要
这次比赛是在6个基座大模型上进行的,真正的投资应该不会使用基座大模型,而是针对金融场景进行微调的领域大模型(比如我在写的那个系列)。但是即使是获取了最大知识库的基座大模型+使用prompt进行简单的知识激发,也能让deepseek表现不俗的投资潜力。这主要可能因为他是量化对冲基金公司(High Flyer-Quant)孵化,因此极有可能在训练过程中使用了大量高质量、领域专属的金融数据集 。这种专业化的训练使其能够更好地理解金融术语、识别市场模式,并内化了量化交易中至关重要的风险控制原则。
或许他们有一个闭源的投资专业大模型在市场上更放肆的收割。
与之形成鲜明对比的是,GPT-5 和 Gemini 等通用模型主要基于广泛的互联网文本进行训练。尽管这赋予了它们渊博的通用知识,但这些知识在需要深度专业理解和严格纪律的金融交易领域显得力不从心。更加凸显了领域化、垂直大模型的必要。
3、AI有个性吗?
根据对他们的交易行为分析,我们发现DeepSeek 的量化基因使其表现得像一个纪律严明的“狙击手”;Grok 对 X 平台数据的依赖使其成为一个追逐热点的“情绪交易者”;而 Gemini 的通用背景可能导致了其在决策时的“摇摆不定”。
虽然我们输入的是同样的prompt和市场指标,但是每个模型做出的反应完全不同,活脱脱的股票场的众生相。我是一个攻壳迷,很容易让我联想起它关于意识和肉体、人类和机械的讨论。 在LLM形成了自己的知识和投资风格之后,他们距离“意识”或者说“Ghost”还有多远?
攻壳有一集讲了一个股票大亨在去世(肉体死亡)之后,将自己的ghost上传到了网络世界,在网络世界继续以ghost的方式炒股赚钱。如今的LLM离它还有多远?
写在最后:智能的马车和醉酒的行人
写到这里,我忽然有些恍惚。
还记得《流浪地球2》刚上映那会儿,我第一次看到 MOSS 的时候,
那种震撼至今难忘——它能实时重写操作系统、理解人类语言、甚至构建数字生命。
那时我还以为,这样的“人工智能”至少要几十年后才会出现。
结果转眼之间,Claude和Cursor、已经能帮我们写代码,Sora已经能生成不错的视频了(是不是数字生命?)。
从 0 到 1 的突破已经完成,而从 1 到 100 的奔跑,正在进行。
让我不禁想起——
1886 年,卡尔·本茨驾驶着世界上第一辆汽车驶过德国曼海姆的街头。
那天,围观的人群惊恐地四散奔逃,
因为那辆冒着烟的“铁马”太吵、太快、太不可思议。
一个世纪之后,我们再次迎来了新的“铁马”——
这次,它不是汽缸,而是神经网络;
不是轮胎的轰鸣,而是算力的轰鸣。
今天,我们质疑 AI 是否真的理解市场;
明天,也许那些不会使用“方向盘”的人类交易员,
会像不会驾驭蒸汽机的车夫一样,被历史悄然淘汰。
但在敬畏的同时,我们也要保持清醒。
我最喜欢的一个学者型作家纳西姆·塔勒布(Nassim Taleb)在《随机漫步的傻瓜》中写道一个经典的比喻:
“一个醉酒的人在路灯下踉跄地走着,看起来似乎在前进, 但他其实只是随机地晃动,偶尔向前一步,全靠运气。”
市场中无数看似聪明的模型、杰出的交易员、DeepSeek
很多时候,也不过是这位“醉酒的行人”。
他们的成功,也许只是随机波动中的一次幸运。
也许不是。
转载请注明:好奇网 » 一篇文章讲清楚大模型炒股靠不靠谱,从Nof1炒股比赛开始