导读
你们是否曾经好奇,在人工智能的江湖中,那些顶尖高手是如何一决高下的?今天,我们就带你走进AI世界的两大门派——DeepMind和OpenAI,揭秘他们背后的强化学习(RL)流派之争。这不仅是技术的较量,更是智慧的碰撞。
1.两大RL流派简介
1.1 DeepMind的Value-based RL

今天我们来聊聊AI圈子里的两大流派之一——DeepMind的Value-based RL。这可是个重磅角色,由David Silver领衔,他的导师是RL领域的大佬Richard Sutton。Sutton老爷子可是出了名的Value-based RL的忠实粉丝,他的书《Reinforcement Learning: An Introduction》几乎成了这个领域的圣经。
Value-based RL的核心思想,就是通过评估每个动作的价值(或者说收益)来做出决策。想象一下,你是个智能体,在游戏世界里,每个动作都可能带来不同的分数,Value-based RL就是要帮你找到那个能带来最高分数的动作。
DeepMind在这个领域可是大放异彩,他们的AlphaGo和AlphaZero就是用Value-based RL搞定的。这些项目不仅在围棋上打败了世界冠军,还展示了AI在复杂任务上的惊人潜力。简单来说,Value-based RL就是让AI学会评估每个动作的长期价值,然后做出最优选择。
1.2 OpenAI的Policy-based RL
接下来,我们来看看另一大流派——OpenAI的Policy-based RL。这个流派的领军人物是Pieter Abbeel和他的两位高徒Sergey Levine和John Schulman。这三位大佬在RL界可是响当当的人物,他们的工作对整个领域产生了深远影响。
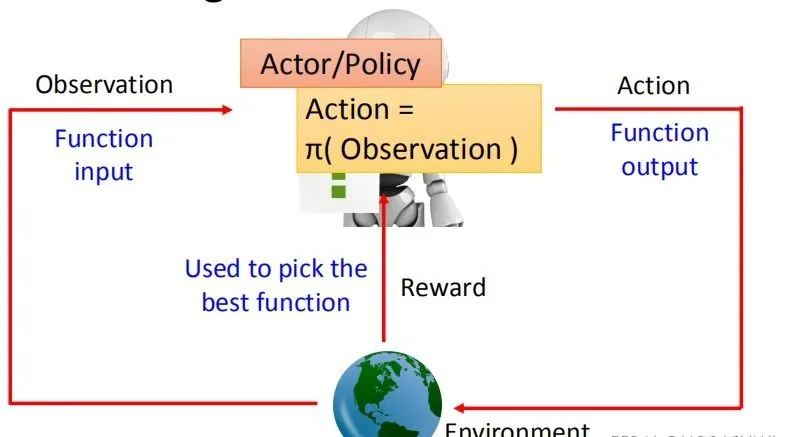
Policy-based RL的出发点是直接学习一个策略函数,这个函数告诉智能体在任何给定状态下应该采取什么动作。这有点像是给AI一个明确的行动指南,而不是让它自己去评估每个动作的价值。
OpenAI在这个方向上的应用特别注重效率和实用性。他们的PPO(Proximal Policy Optimization)算法就是Policy-based RL的代表作,这个算法以其出色的性能和稳定性在RL界广受欢迎。而且,Policy-based RL在机器人领域尤其吃香,因为它能处理样本效率问题,这对于昂贵且易损坏的机器人来说至关重要。
总的来说,两大流派各有千秋。DeepMind的Value-based RL更注重理论研究和算法创新,而OpenAI的Policy-based RL则更看重效率和实用性。这两种方法都有各自的优势和应用场景,也让我们看到了AI在不同领域的无限可能。
2. Value-based RL的特点
2.1以价值函数为核心
首先得说,Value-based RL的心脏就是价值函数,这可是它的核心竞争力。价值函数,听起来是不是有点像游戏里的得分榜?没错,它就是用来衡量每个动作能带来多少“分数”的。
在Value-based RL的世界里,智能体就像是在玩一个大型游戏,每个动作都可能带来不同的结果。比如在玩《超级马里奥》时,你是选择跳过这个沟,还是尝试踩扁那个乌龟?Value-based RL就是用来帮智能体预测,哪个动作能让它走得更远,得分更高。
2.2强调规划与学习的结合
接下来,咱们得聊聊Value-based RL的另一个杀手锏——规划与学习的结合。这就像是智能体不仅要会玩,还得学会制定策略。想象一下,你是个棋手,不仅要走好每一步棋,还得想好接下来的几步怎么走。Value-based RL就是这样,它通过学习来预测每个动作的长期价值,然后通过规划来选择最优的动作序列。
DeepMind的AlphaGo就是个好例子。它不仅学会了评估每一步棋的价值,还学会了如何规划接下来的几步棋。这就是为什么AlphaGo能够打败世界围棋冠军的原因,它不仅看到了眼前的一步,还看到了未来的许多步。
总的来说,Value-based RL就像是智能体的智囊团,不仅告诉它每个动作的价值,还帮它规划出一条最佳路径。这种方法在处理复杂任务时特别有用,比如下棋、玩游戏,甚至是更复杂的决策问题。它让AI不仅能够应对眼前的情况,还能够预见未来,做出更明智的选择。
3. Policy-based RL的特点
3.1以策略函数为核心
和Value-based RL不一样,Policy-based RL的大招是直接学习一个策略函数。这个策略函数就像是智能体的行动指南,告诉它在每个状态下应该做什么。
想象一下,你是个新手司机,Policy-based RL就像是你的驾校教练,直接教你在每个路口怎么开车,而不是让你自己去想每个动作能带来多少分数。这种方法更直接,也更高效,特别是在动作空间很大或者连续的情况下。
3.2强调样本效率和直接策略优化
Policy-based RL的另一个亮点就是它对样本效率的重视。这是什么意思呢?简单来说,就是Policy-based RL能够用更少的尝试来学习一个好的策略。这在机器人学习或者其他需要大量实验的领域特别重要,因为实验成本可能很高。
而且,Policy-based RL还强调直接策略优化。这意味着它会直接对策略进行微调,而不是通过价值函数来间接影响策略。这样做的好处是,我们可以更快地改进策略,因为它直接作用于智能体的行为。
举个例子,OpenAI的PPO算法就是这样。它通过限制策略更新的步长,确保智能体不会突然做出太大的改变,从而避免性能下降。这种方法就像是在教智能体走路,一步步来,而不是一下子跳得太远。
总的来说,Policy-based RL就像是给智能体一个明确的行动计划,让它能够快速学习和适应环境。这种方法在需要快速学习和决策的场景下特别有用,比如自动驾驶、机器人控制等领域。它让AI能够更加灵活和高效地做出决策。
4.两大流派的差异
首先,来聊聊DeepMind和OpenAI这两大RL流派在实际应用中都有哪些不同。
4.1 DeepMind的应用场景
DeepMind的Value-based RL在应用上更注重理论研究和算法创新。他们的AlphaGo和AlphaZero就是最好的例子,这些项目不仅在围棋上打败了世界冠军,还展示了AI在复杂任务上的惊人潜力。
-围棋与棋类游戏:DeepMind的AlphaGo通过Value-based RL学会了评估每一步棋的价值,并规划出最优的棋局策略,这在围棋这类需要深度策略思考的游戏中表现得尤为突出。
-复杂任务解决:AlphaZero则进一步证明了Value-based RL在处理没有明确规则的复杂任务上的能力,它通过自我对弈学习,不需要人类数据就能达到超人水平。
-科学研究:DeepMind还将Value-based RL应用于科学研究,比如蛋白质折叠预测,这在生物学和医学领域具有重大意义。
4.2 OpenAI的应用场景
OpenAI的Policy-based RL则更看重效率和实用性,特别是在机器人和需要快速决策的场景中。
-机器人控制:Policy-based RL在机器人控制领域特别受欢迎,因为它能处理样本效率问题,这对于昂贵且易损坏的机器人来说至关重要。例如,OpenAI的研究人员使用Policy-based RL训练机器人完成复杂的操控任务。
-自动驾驶:在自动驾驶领域,Policy-based RL可以帮助车辆快速学习和适应各种路况,因为它能直接优化驾驶策略,提高决策的效率和准确性。
-游戏AI:OpenAI的GPT系列模型在自然语言处理方面表现出色,但也被用于游戏AI的开发,比如Dota 2和StarCraft II的AI对手,这些AI能够快速学习和适应游戏环境。
总的来说,DeepMind的Value-based RL在需要深度策略思考和长期规划的应用中表现出色,而OpenAI的Policy-based RL则在需要快速学习和决策的场景中更为高效。
接下来,再来深入探讨一下DeepMind和OpenAI这两大RL流派在哲学和方法论上的差异。这不仅仅是技术的问题,更关乎我们如何看待AI的发展和未来。
4.3理论驱动与通用智能追求
DeepMind的Value-based RL流派,可以说是理论驱动的代表。他们追求的是通用智能(AGI),也就是那种能够像人类一样在各种任务上都能表现出智能的AI。
-理论深度:DeepMind的研究深受David Silver的影响,他和他的导师Richard Sutton都是RL理论的大师。他们的工作强调对RL理论的深入理解和发展,比如Markov Decision Process、Dynamic Programming等,这些都是控制论和优化理论中的经典方法。
-通用智能目标:DeepMind的目标是打造能够处理各种复杂任务的AI,比如他们的AlphaGo和AlphaZero项目,就是通过Value-based RL来实现的。这些项目展示了AI在围棋等复杂任务上的潜力,也让我们看到了通用智能的可能性。
-长期投资:DeepMind在Value-based RL上的投入是长期的,他们不追求短期的商业回报,而是致力于解决AI领域的根本问题。这种长期的视角使得他们能够在理论上取得突破,但也意味着他们的成果可能需要较长时间才能转化为实际应用。
4.4实用主义与效率优先
相比之下,OpenAI的Policy-based RL流派则更注重实用主义和效率优先。
-效率和实用性:OpenAI的研究更侧重于算法的效率和实用性。他们的Policy-based RL算法,如PPO,以其出色的性能和稳定性在RL界广受欢迎。这种方法更直接,能够快速地优化策略,使其在实际应用中更加高效。
-样本效率:在机器人和其他需要大量实验的领域,样本效率尤为重要。Policy-based RL能够用更少的数据来学习有效的策略,这对于成本高昂的实验来说是一个巨大的优势。
-快速迭代:OpenAI的研究强调快速迭代和应用。他们的算法更注重短期内能够产生效果,这使得他们的研究成果能够更快地转化为实际的产品和解决方案。
-商业化考量:OpenAI在研究的同时,也考虑到了商业化的可能性。他们的研究不仅追求技术上的突破,也寻求能够带来商业价值的应用,这使得他们的研究成果更容易被市场接受。
总之,DeepMind和OpenAI的两大RL流派在哲学和方法论上的差异,体现了他们对AI发展的不同理解和追求。DeepMind更注重理论研究和通用智能的长远目标,而OpenAI则更看重算法的效率和实用性,以及快速迭代和商业化的可能性。这两种不同的视角,为我们探索AI的未来提供了多样化的路径。
6.总结
总的来说,这两大RL流派就像是AI世界的两盏明灯,它们各自照亮了AI发展的不同方向,也让我们对未来的AI充满了更多的期待和想象。无论是DeepMind的Value-based RL还是OpenAI的Policy-based RL,它们都在以自己的方式推动着AI的进步,让我们拭目以待,看看这两个流派会在未来给我们带来什么样的惊喜吧!
转载请注明:好奇网 » 强化学习2大流派PK!DeepMind与OpenAI的选谁?