导读
今天我们来聊聊一个听起来可能有点技术宅,但实际上超级酷的话题——强化学习。想象一下,你正在玩一款新游戏,没有教程,没有攻略,你只能靠自己摸索,通过不断尝试和犯错来学会游戏规则,逐渐成为高手。这个过程,其实就是强化学习的核心思想。
1、强化学习的定义
强化学习,就像它的名字一样,是通过“强化”某些行为来学习的过程。在这个过程中,我们的“学生”是一个智能体(可以是一个AI程序,也可以是一个机器人),而“老师”则是环境。智能体在环境中做出各种动作,环境根据这些动作给出反馈,反馈的形式是奖励或者惩罚。智能体的目标就是通过这些反馈来学习,以便在未来能够做出更好的决策,获得更多的奖励。

举个例子,假设你是一个智能体,你的任务是在一个迷宫里找到出口。你每走一步,迷宫都会告诉你是对还是错。如果你走对了,迷宫可能会给你一些“奖励”,比如金币或者分数;如果你走错了,可能会有“惩罚”,比如时间损失或者生命值减少。你的任务就是通过这些奖励和惩罚来学习,找到一条最快的路径逃出迷宫。
在强化学习的世界里,我们不直接告诉智能体应该怎么做,而是让它通过与环境的互动自己“悟”出来。这种方式有点像我们人类学习新技能的过程,不是吗?通过不断的尝试和错误,我们学会了骑自行车、做饭、甚至是处理复杂的人际关系。
所以,强化学习不仅仅是一种编程技术,它更是一种模拟生物学习过程的方法。它让机器能够像生物一样,通过与环境的互动来学习和适应。这就是强化学习的魅力所在,也是为什么它在人工智能领域如此受欢迎的原因。
2、强化学习的核心概念
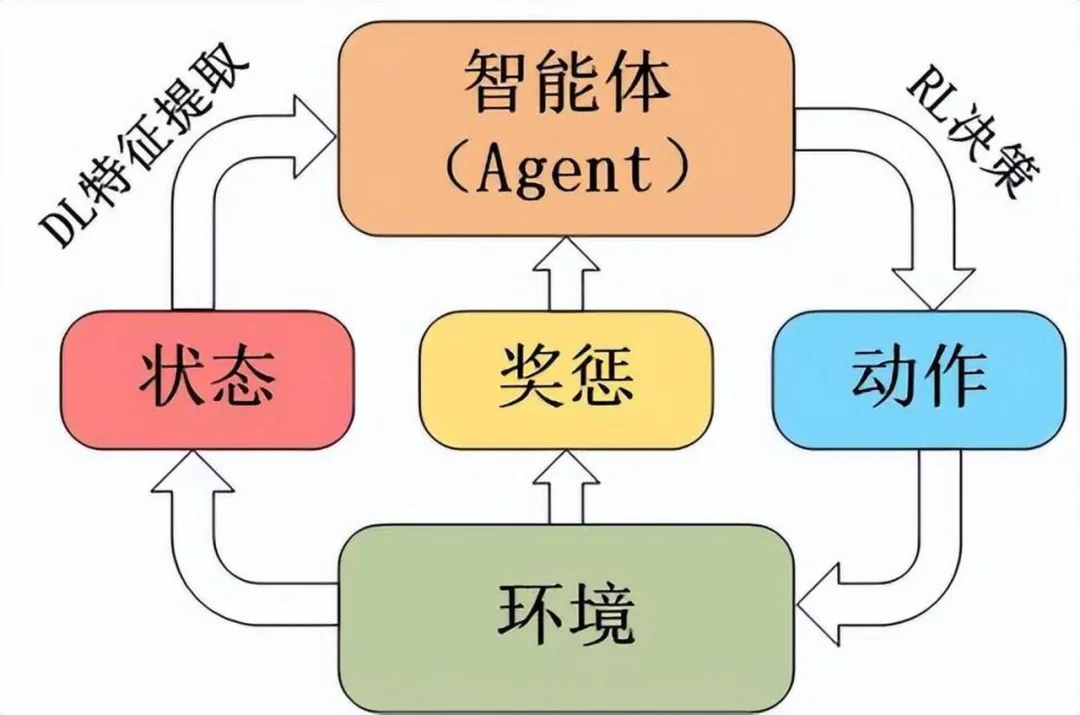
2.1 智能体与环境
聊完定义,再来聊聊强化学习中的两个关键角色:智能体和环境。想象一下,智能体就像是一个探险家,而环境就是他要探索的未知世界。这个探险家(智能体)要在这个世界(环境)中找到宝藏,但他不知道宝藏在哪里,只能通过不断地尝试和环境给他的线索(反馈)来学习如何找到宝藏。
智能体需要做的,就是在这个环境中做出各种动作,比如走左边的路或者走右边的路。每做一个动作,环境就会给他一些反馈,告诉他这个动作是好是坏。这个反馈就是我们说的“奖励”或者“惩罚”。如果智能体选对了路,环境可能会给他一些奖励,比如金币或者分数;如果选错了,可能会有惩罚,比如时间损失或者生命值减少。
这个过程就像是我们玩电子游戏一样。游戏里的角色(智能体)通过不断地尝试和犯错,学会了如何过关斩将,最终达到游戏的目标。强化学习就是让机器通过这种方式来学习,是不是很酷?
2.2 状态、动作和奖励
接下来,我们来聊聊强化学习中的三个核心概念:状态、动作和奖励。
首先,“状态”就是智能体所处的环境的当前情况。比如在迷宫游戏中,智能体的状态可能就是它当前在迷宫的哪个位置。在更复杂的环境中,状态可能包括更多信息,比如智能体的速度、周围物体的位置等等。
然后是“动作”,动作就是智能体在某个状态下可以做的事情。比如在迷宫游戏中,动作可能就是“向前走”、“向左走”或“向右走”。智能体需要决定在每个状态下应该采取哪个动作。
最后,我们来说说“奖励”。奖励是环境对智能体动作的反馈。如果智能体做了一个好动作,环境会给正奖励,比如分数或者金币;如果做了一个不好的动作,可能会给负奖励,比如扣分或者生命值减少。智能体的目标就是通过学习如何在不同状态下选择动作,来最大化获得的总奖励。
这三个概念就像是强化学习的三块基石,智能体通过不断地与环境互动,学习如何在不同的状态下做出最好的动作,以获得最多的奖励。这个过程就像是我们人类学习新技能一样,通过不断的尝试和错误,我们学会了骑自行车、做饭,甚至是处理复杂的人际关系。
3、 强化学习的决策过程
下面继续深入探讨强化学习的世界,特别是它是怎么做出决策的。想象一下,我们的智能体(AI探险家)现在不仅要在迷宫中找到出口,还要学会怎样走才能拿到最多的金币,这就是强化学习的决策过程。
在强化学习中,智能体做决策主要依靠两个东西:策略和价值函数。
策略(Policy)就像是智能体的“大脑”。它告诉智能体在每个状态下应该采取哪个动作。比如,在一个迷宫游戏中,策略可能会告诉智能体:“如果你在迷宫的这个位置,那就往右走。”策略的目标是最大化智能体获得的总奖励。
我们可以把策略想象成一张地图,上面标满了在不同地点应该采取的行动。智能体只需要按照这张地图走,就能尽可能地收集到最多的金币并找到出口。
价值函数(Value Function)则是智能体的“评分系统”。它给每个状态或动作一个“分数”,告诉智能体这个状态或动作有多好。比如,如果智能体在一个有很多金币的房间里,价值函数会给这个状态一个高分。相反,如果一个动作会导致智能体掉入陷阱,价值函数会给这个动作一个低分。
价值函数就像是智能体的“直觉”,帮助它判断哪个选择更好。通过不断地学习和调整,智能体的“直觉”会变得越来越准确,帮助它做出更好的决策。
在强化学习中,策略和价值函数是相辅相成的。智能体根据价值函数的评分来调整自己的策略,而策略的执行结果又反过来更新价值函数的评分。这个过程就像是智能体在不断地学习和进步,最终成为一个“高手”。
通过这种方式,强化学习让智能体能够自主地学习和适应环境,找到最佳的行动方案。这就是为什么强化学习在游戏、机器人控制、自动驾驶等领域如此受欢迎的原因。
4、强化学习的算法类型
就像是在游戏世界里,我们有各种各样的技能和武器来战胜敌人,强化学习也有不同的算法来帮助智能体在复杂的环境中做出最佳决策。
强化学习算法可以根据其核心思想和实现机制被分为几个主要类别。以下是强化学习算法的主要归类,以及每个类别的关键特点和应用场景。
4.1 基于值的算法 (Value-Based Algorithms)
基于值的算法直接学习状态或状态-动作对的价值函数,而不显式地学习策略。这些算法的核心在于评估每个状态或动作的长期价值,然后根据这些价值来选择动作。
- Q-Learning:一种无模型的强化学习算法,通过学习一个动作价值函数(Q函数),该函数估计在给定状态下采取每个可能动作的预期回报。
- Sarsa:与Q-Learning类似,但Sarsa同时考虑了当前策略,它通过交互采样来更新价值函数,即智能体实际采取的动作被用来更新价值估计。
- Deep Q-Network (DQN):结合了深度学习与Q-Learning,使用深度神经网络来近似Q函数,特别适用于高维输入空间的问题。
4.2 基于策略的算法 (Policy-Based Algorithms)
基于策略的算法直接学习策略,即直接学习状态到动作的映射。这些算法通常使用策略梯度方法,通过优化策略来增加期望回报。
- Policy Gradient:一种基于梯度的方法,通过直接对策略函数进行梯度上升来优化策略。
- Actor-Critic Methods:结合了策略网络(Actor)和价值网络(Critic),Actor负责生成动作,Critic负责评估当前策略的好坏,以此来指导Actor的更新。
4.3 基于模型的算法 (Model-Based Algorithms)
基于模型的算法试图学习环境的模型,即状态转移概率和奖励函数。通过拥有环境模型,智能体可以在模型中进行规划,以找到最优策略。
- Dynamic Programming:通过解决贝尔曼方程来找到最优价值函数和最优策略,适用于小规模或完全可观察的环境。
- Monte Carlo Tree Search (MCTS):结合了蒙特卡洛方法和树搜索,用于决策过程中的规划和探索,特别适用于游戏和模拟环境中的决策。
4.4 混合算法 (Hybrid Algorithms)
混合算法结合了上述两种或多种方法的特点,以利用各自的优势。
- Actor-Critic with Experience Replay:结合了Actor-Critic方法和经验回放机制,经验回放允许算法从过去的经验中学习,提高了数据的利用率。
- Deep Deterministic Policy Gradient (DDPG):结合了策略梯度和价值函数估计,使用深度学习来处理连续动作空间的问题。
这些算法类别并不是互斥的,许多现代的强化学习算法结合了多种方法的特点,以适应不同的应用场景和提高学习效率。随着研究的深入,新的算法和变种不断涌现,强化学习领域保持着活跃的发展态势。
5、强化学习的实际应用
你们可能已经听说过强化学习在游戏和自动驾驶等领域的大名,但具体是怎么一回事呢?让我们一起来一探究竟!
5.1 游戏AI
在游戏的世界里,强化学习就像是给AI开了挂。想象一下,你在游戏中的对手不是由程序员硬编码的,而是一个能够自我学习和进化的AI,这是不是听起来就很刺激?
如何工作?强化学习让AI通过与游戏环境的互动来学习如何玩。AI会尝试不同的策略,根据游戏的反馈(比如得分或者游戏结束)来调整自己的行为。这样,AI就能逐渐学会如何在游戏中取得高分或者赢得比赛。
数据说话。根据最新的研究,使用强化学习的AI在《Dota 2》和《星际争霸II》等复杂策略游戏中已经能够与人类高手抗衡。在《Dota 2》中,由强化学习训练的AI“OpenAI Five”甚至击败了99.5%的人类玩家。
这种技术的应用不仅仅局限于PC游戏。在手机游戏、棋类游戏甚至卡牌游戏中,强化学习都在帮助AI变得更加强大和智能。
5.2 自动驾驶
接下来,我们聊聊自动驾驶。强化学习在这里的应用,就像是给汽车装上了一个不断学习和进化的大脑。
如何工作?在自动驾驶汽车中,强化学习帮助车辆学习如何在复杂的交通环境中做出最佳决策。车辆通过传感器收集环境信息,然后根据这些信息来决定如何行驶。强化学习算法会让车辆根据行驶的结果(比如是否安全、是否高效)来调整自己的行为。
数据说话:根据Waymo(谷歌的自动驾驶公司)的数据,他们的自动驾驶汽车已经在公共道路上安全行驶了超过2000万英里。这些行驶里程中,强化学习算法帮助车辆不断学习和适应各种复杂的交通情况。
强化学习的应用不仅限于决策制定,它还在自动驾驶的感知、规划和控制等多个方面发挥作用。通过强化学习,自动驾驶汽车能够更好地理解交通规则,预测其他车辆和行人的行为,从而做出更安全、更高效的决策。
6、强化学习的挑战与未来
最后,再来聊聊强化学习面临的挑战和未来的发展方向。虽然强化学习在游戏、自动驾驶等领域取得了令人瞩目的成就,但它仍然面临着一些挑战,同时也有着巨大的潜力等待我们去挖掘。
6.1 挑战:数据稀疏性
强化学习的一个主要挑战是数据稀疏性。在现实世界中,智能体往往需要大量的尝试和错误才能学会一个任务,这意味着需要大量的数据。然而,在许多应用场景中,获取这些数据是非常昂贵甚至是不可能的。
数据说话:例如,在医疗领域,智能体可能需要通过大量的病例来学习如何诊断疾病,但每个病例都是宝贵的,不能轻易地用于实验。因此,如何有效地利用有限的数据来训练强化学习模型,是一个亟待解决的问题。
6.2 挑战:训练稳定性
另一个挑战是训练的稳定性。强化学习算法往往对初始参数和超参数非常敏感,这可能导致训练过程中的不稳定,甚至导致学习失败。
数据说话:根据最新的研究,即使是在标准的强化学习基准测试中,不同的算法和参数设置也会导致性能的显著差异。这表明,我们需要更多的研究来理解和控制强化学习算法的训练动态,以确保它们的稳定性和可靠性。
6.3 挑战:可解释性和安全性
随着强化学习在关键领域(如自动驾驶和医疗)的应用,算法的可解释性和安全性变得越来越重要。我们需要能够理解和信任智能体的行为,特别是在它们做出重要决策时。
数据说话:根据一项调查,超过70%的专业人士表示,他们对在关键任务中使用强化学习算法持保留态度,主要原因是对算法的可解释性和安全性的担忧。这强调了在强化学习领域中,提高算法的透明度和可解释性的重要性。
6.4 未来:多智能体系统
强化学习的未来发展方向之一是多智能体系统。在这些系统中,多个智能体需要学习如何协作或竞争,以达到共同的目标或实现各自的目标。
数据说话:研究表明,多智能体系统在交通管理、电网控制等领域有着巨大的应用潜力。通过强化学习,这些系统可以更有效地响应环境变化,提高整体效率和稳定性。
6.5 未来:跨领域融合
最后,强化学习的未来还可能在于与其他领域的融合,如深度学习、自然语言处理等。这种跨领域的融合可以为强化学习带来新的思路和方法,同时也为其他领域提供新的解决方案。
数据说话:例如,结合深度学习和强化学习的算法已经在图像识别和自然语言理解等领域取得了突破性进展。这些进展表明,强化学习与其他领域的结合,将为人工智能的发展开辟新的可能性。
7. 总结
强化学习的本质是通过与环境的互动来学习。我们的“学生”是一个智能体,而“老师”则是环境。智能体在环境中做出各种动作,环境根据这些动作给出反馈,反馈的形式是奖励或者惩罚。智能体的目标就是通过这些反馈来学习,以便在未来能够做出更好的决策,获得更多的奖励。
强化学习的应用范围非常广泛,从游戏AI到自动驾驶,再到医疗和金融等领域,强化学习都在帮助机器变得更加智能和强大。它让机器能够自主地学习和适应环境,找到最佳的行动方案。
尽管强化学习取得了令人瞩目的成就,但它仍然面临着数据稀疏性、训练稳定性、可解释性和安全性等挑战。同时,多智能体系统和跨领域融合等方向为强化学习的未来提供了巨大的潜力和机遇。
转载请注明:好奇网 » 5000字!通俗易懂的讲清楚强化学习