强化学习:让模型从经验中学习
人类和 LLMs 处理信息的方式截然不同。我们直观理解的简单算术,对 LLMs 来说只是文本标记的序列。相反,LLMs 能够在复杂话题上生成专家级别的回应,仅仅是因为它们在训练中见过足够的例子。这种认知差异使得人类标注者很难提供一套 “完美” 的标签,始终引导 LLMs 得出正确答案。
强化学习(RL)弥合了这一差距,它允许模型从自己的经验中学习。模型不再完全依赖显式的标签,而是通过探索不同的文本序列,并接收反馈——奖励信号——来判断哪些输出更有用。随着时间的推移,模型逐渐学会更好地符合人类的意图。
强化学习的直观理解
LLMs 具有随机性,这意味着它们的回应不是固定的。即使面对相同的提示,输出也会有所不同,因为它们是从概率分布中采样得到的。我们可以利用这种随机性,通过并行生成数千甚至数百万种可能的回应,让模型探索不同的路径——有些好,有些坏。我们的目标是鼓励模型更频繁地选择更好的路径。
为了实现这一点,我们训练模型学习那些导致更好结果的标记序列。与监督微调不同,强化学习让模型自己学习。模型发现哪些回应最有效,每次训练步骤后,我们更新它的参数。随着时间的推移,这使得模型在面对类似的提示时,更有可能生成高质量的答案。
但如何确定哪些回应是最好的呢?我们又该进行多少强化学习?这些细节非常棘手,正确处理它们并不容易。
强化学习并非 “新” 概念:AlphaGo 的启示
强化学习的强大威力在 DeepMind 的 AlphaGo 中得到了充分体现,这是第一个击败专业围棋选手并最终超越人类水平的 AI。在 2016 年的《自然》论文中,当模型仅通过监督微调(SFT)进行训练时,它能够达到人类水平的表现,但从未超越它。这是因为 SFT 关注的是复制,而不是创新——它不允许模型发现超出人类知识的新策略。
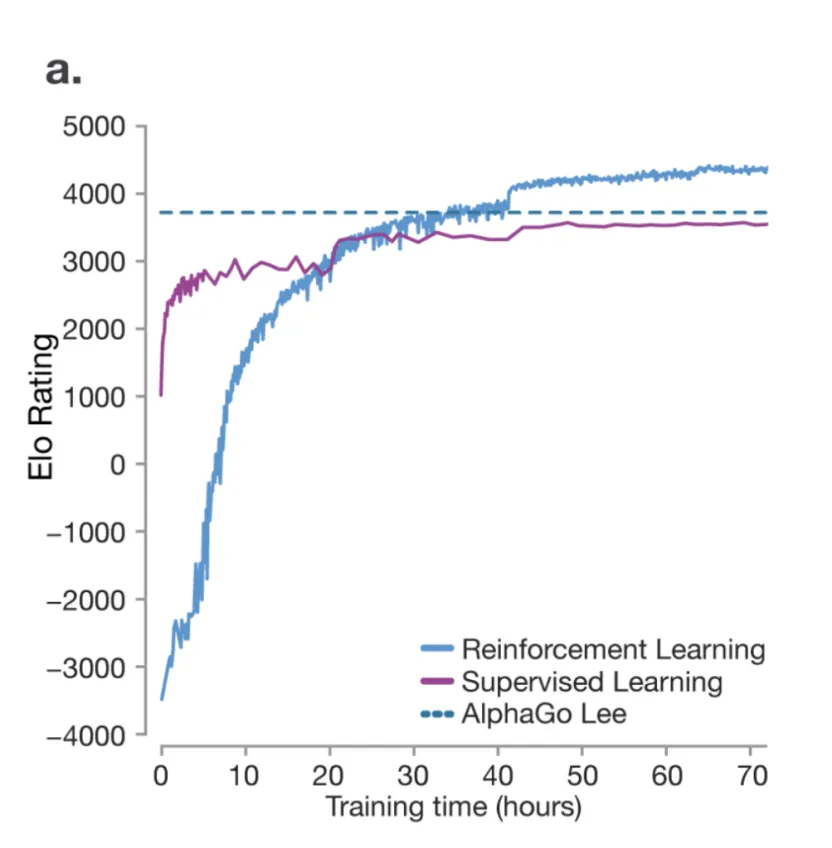
然而,强化学习使 AlphaGo 能够与自己对弈,完善策略,最终超越人类专家(蓝线)。
AlphaGo 的成功表明,强化学习在 AI 领域代表着一个令人兴奋的前沿——当模型在多样化且具有挑战性的问题池上进行训练时,它们可以探索超出人类想象的策略,从而优化其思维策略。
强化学习基础回顾
让我们快速回顾一下典型强化学习设置的关键组件:
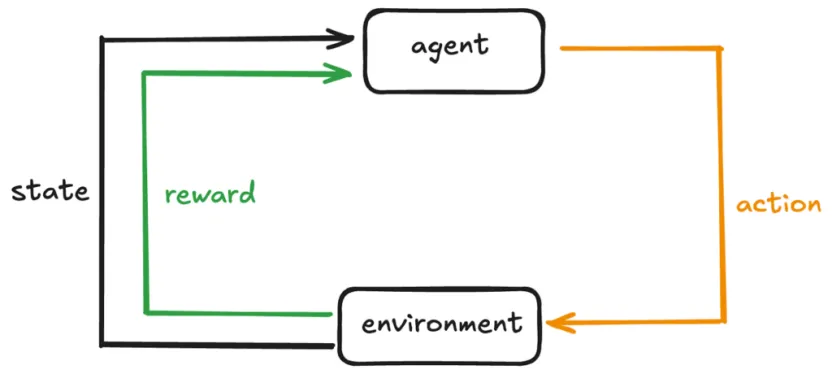
- 智能体(Agent):学习者或决策者。它观察当前状态,选择一个动作,然后根据结果(奖励)更新其行为。
- 环境(Environment):智能体所处的外部系统。
- 状态(State):在给定时间步 t 的环境快照。
- 动作(Action):智能体在环境中执行的动作,这将改变环境的状态。
- 奖励(Reward):反馈,以数值形式表示,正奖励鼓励某种行为,负奖励则抑制它。
通过从不同状态和动作中获取反馈,智能体逐渐学会最优策略,以最大化随时间累积的总奖励。
策略(Policy)
策略是智能体的行动策略。如果智能体遵循良好的策略,它将始终做出明智的决策,从而在多个步骤中获得更高的奖励。在数学上,它是一个函数,确定给定状态下不同输出的概率(πθ(a|s))。
价值函数(Value Function)
价值函数是对处于某个状态有多好的估计,考虑到长期预期奖励。对于 LLMs,奖励可能来自人类反馈或奖励模型。
行为者 – 批评者架构(Actor-Critic Architecture)
这是一种流行的强化学习设置,结合了两个组件:
行为者(Actor):学习并更新策略(πθ),决定在每个状态下采取哪个动作。
批评者(Critic):评估价值函数(V(s)),向行为者提供反馈,告知其选择的动作是否导致了好的结果。
工作原理如下:
行为者 根据当前策略选择一个动作。
批评者 评估结果(奖励 + 下一个状态),并更新其价值估计。
批评者的反馈帮助行为者优化策略,使未来的动作带来更高的奖励。
将强化学习应用于 LLMs
对于 LLMs,状态可以是当前文本(提示或对话),动作可以是生成的下一个标记。奖励模型(例如人类反馈)会告诉模型其生成的文本有多好或有多坏。策略是模型选择下一个标记的策略,而价值函数估计当前文本上下文有多有益,就最终产生高质量回应而言。
深度探索 R1(DeepSeek-R1)
为了突出强化学习的重要性,深入探讨一下深度探索 R1(DeepSeek-R1),这是一个在保持开源的同时实现顶级性能的推理模型。该论文介绍了两个模型:DeepSeek-R1-Zero 和 DeepSeek-R1。
DeepSeek-R1-Zero 仅通过大规模强化学习进行训练,跳过了监督微调(SFT)。
DeepSeek-R1 在此基础上,解决了遇到的挑战。
1. 强化学习算法:组相对策略优化(GRPO)
组相对策略优化(GRPO)是一种关键的强化学习算法,是广受欢迎的近端策略优化(PPO)的一个变体。GRPO 于 2024 年 2 月在 DeepSeekMath 论文中引入。
为什么选择 GRPO 而不是 PPO?
PPO 在推理任务中存在以下问题:
- 依赖批评者模型, effectively doubling memory and compute.
- 训练批评者模型可能很复杂,尤其是对于细微或主观的任务。
- 高计算成本,因为强化学习管道需要大量资源来评估和优化回应。
- 绝对奖励评估:当依赖绝对奖励时——即有一个单一标准或指标来判断答案是 “好” 还是 “坏”——很难捕捉不同推理领域中开放式、多样化任务的细微差别。
GRPO 如何解决这些挑战:
GRPO 通过使用相对评估来消除批评者模型——在组内比较回应,而不是根据固定标准进行判断。
想象学生们在解决一个问题。不是老师单独给他们打分,而是他们互相比较答案,从彼此身上学习。随着时间的推移,表现逐渐趋于更高质量。
GRPO 如何融入整个训练过程:
1. 收集数据(查询 + 回应):对于 LLMs,查询就像问题一样,旧策略(模型的旧快照)为每个查询生成多个候选答案。
2. 分配奖励:组内的每个回应都会被评分(“奖励”)。
3. 计算 GRPO 损失:传统上,你会计算一个损失——显示模型预测与真实标签之间的偏差。在 GRPO 中,你衡量:
- 新策略产生过去回应的可能性有多大?
- 这些回应是相对更好还是更差?
- 应用裁剪以防止极端更新。
- 这产生一个标量损失。
4. 反向传播 + 梯度下降:反向传播计算每个参数对损失的贡献,梯度下降更新这些参数以减少损失。经过多次迭代,这逐渐使新策略倾向于选择奖励更高的回应。
5. 偶尔更新旧策略以匹配新策略:这为下一轮比较刷新了基线。
2. 思维链(CoT)
传统的 LLM 训练遵循预训练 → 监督微调 → 强化学习。然而,DeepSeek-R1-Zero 跳过了监督微调,让模型直接探索思维链推理。
就像人类思考一个棘手的问题一样,思维链使模型能够将问题分解为中间步骤,提升复杂推理能力。OpenAI 的 o1 模型也利用了这一点,正如其 2024 年 9 月的报告中所指出的:o1 的性能随着更多强化学习(训练时计算)和更多推理时间(测试时计算)而提高。
DeepSeek-R1-Zero 展现出反思倾向,自主完善其推理。论文中的一个关键图表(如下)显示,训练过程中思维的增加导致了更长(更多标记)、更详细和更好的回应。
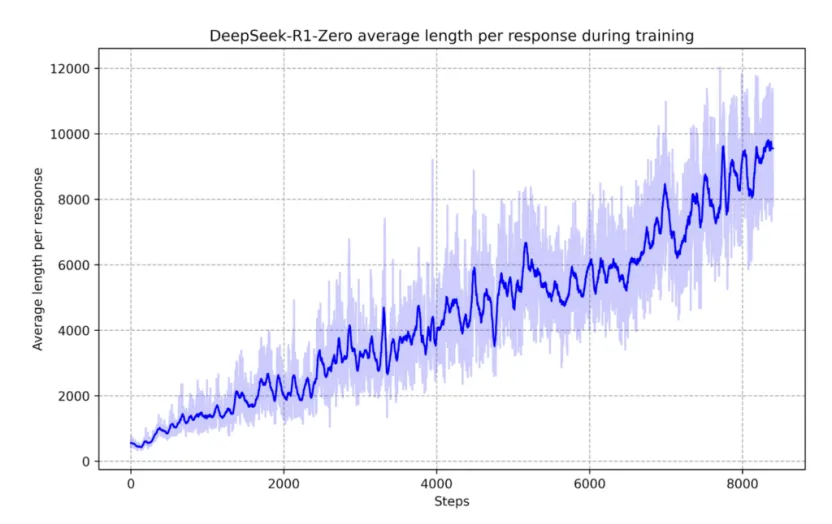
没有明确的编程,它开始重新审视过去的推理步骤,提高了准确性。这突显了思维链推理作为强化学习训练的一个新兴特性。
模型还有一个 “顿悟时刻”(如下图)—— 这是强化学习如何导致意外且复杂的结果的一个有趣例子。

需要注意的是,与 DeepSeek-R1 不同,OpenAI 在 o1 中没有展示完整的精确思维链,因为他们担心蒸馏风险——即有人进来试图模仿这些推理轨迹,并通过模仿恢复大量的推理性能。相反,o1 只总结了这些思维链。
带人类反馈的强化学习(RLHF)
对于具有可验证输出的任务(例如数学问题、事实问答),AI 回应很容易评估。但对于总结或创意写作等领域,没有单一的 “正确” 答案,该怎么办?
这就是人类反馈发挥作用的地方——但天真的强化学习方法是不可扩展的。
让我们看看一个天真的方法,假设一些任意的数字:
假设我们有 10 亿个回应需要评估,每个回应需要 1 个人类评估者花费 1 分钟。这需要 1 亿个人类评估者工作 1 小时,成本高达 10 亿美元!这太昂贵、太慢且不可扩展。因此,一个更聪明的解决方案是训练一个 AI “奖励模型” 来学习人类偏好,大幅减少人类工作量。
对回应进行排名也比绝对评分更容易、更直观。
RLHF 的优势
- 可以应用于任何领域,包括创意写作、诗歌、总结和其他开放式任务。
- 对人类标注者来说,排名输出比生成创意输出本身容易得多。
RLHF 的劣势
- 奖励模型是一个近似值——可能无法完全反映人类偏好。
- 强化学习擅长利用奖励模型——如果运行时间过长,模型可能会利用漏洞,生成无意义但得分高的输出。
需要注意的是,RLHF 与传统强化学习不同。对于经验性、可验证的领域(例如数学、编程),强化学习可以无限期地运行并发现新策略。而 RLHF 更像是一个微调步骤,使模型与人类偏好保持一致。
转载请注明:好奇网 » 为啥大模型需要强化学习?